


1. Yara란
Yara는 문자열이나 바이너리 패턴을 기반으로 악성코드를 검색하며 이러한 악성코드를 분류할 수 있게 하는 도구이다. C와 Python과 같은 문법으로 Yara Rule을 작성하는 것으로 악성코드가 어떤 기능을 하는지, 어떠한 조건에 포함되는지를 쉽게 확인할 수 있으므로 많이 사용되고 있다. Yara는 설명, 이름 규칙, 문자열의 집합 그리고 Bool 식으로 규칙 로직을 결정한다. 또한, 단순히 문자열과 바이너리 패턴만을 이용해서 파일의 시그니처를 찾는 것뿐만 아니라, 특정 Entry Point 값을 지정하거나, File Offset, Virtual Memory Address를 제시하고 정규 표현식을 이용하여 효율적인 패턴 매칭이 가능하다.
1.1 Yara 설치
Yara는 리눅스, 맥, 윈도우 시스템 모두에서 사용할 수 있으며, 소스코드를 직접 컴파일하거나 Yara 실행파일을 직접 실행할 수 있고, Yara-Python 확장을 통해 Python을 통해서도 Yara를 사용할 수가 있다. 이러한 방법 중 Yara를 가장 많이 사용하는 리눅스와 윈도우에서 설치하는 방법에 대해 알아보자.
Linux
Yara 사이트(https://plusvic.github.io/yara/)에서 Download Latest release를 통해 이동해 Source Code - tar.gz를 다운로드한다. 그 후 다음과 같은 과정을 통해 설치를 해주면 되는 것으로 첫 번째 라인에서 많은 항목을 설치하는 것 같지만, 해당 항목이 존재하지 않으면 설치 과정에 오류가 생길 수 있다.

리눅스에서 파이썬으로 사용하고자 할 경우 위에서 압축을 해제한 yara의 폴더에 존재하고 있는 yara-python 폴더에서 다음과 같은 명령어를 입력해주면 된다.

Windows
윈도우의 경우도 마찬가지로 사이트에 접속한 뒤 "Windows binaries can be found 'here'"에서 바로 실행시킬 수 있는 yara나 Python을 이용하는 yara-python을 버전에 맞게 다운로드한다. yara.exe의 경우 바로 실행하여 사용할 수 있으며 yara-python의 경우 다운로드된 yara-pythonx.x.x.win32-pyx.x.exe를 실행시키면 자동으로 yara-python 설치 작업이 완료된다. yara-python이 설치되면 다음과 같은 방법을 통해 사용할 수 있다.

1.2 Usage
Yara는 사용자가 정의한 규칙에 따라 동작하며 이러한 규칙을 어떻게 만드느냐에 따라 Yara는 사용가치가 더욱 올라간다. 우선 규칙에 대한 기초적인 부분을 알아보자. 규칙이 최소한으로 갖추어야 할 형태는 아래의 그림과 같으며, 여기서 검사하고자 하는 파일이 rule의 condition 조건에 TRUE가 될 경우, Yara 명령을 실행했을 때 규칙에 맞음을 출력하고 condition 조건에 False가 되면 기본적으로는 출력되지 않는다.

여기서 규칙의 이름은 영숫자와 밑줄 문자를 포함할 수 있지만, 첫 번째 문자는 숫자를 사용하면 안 된다. 또한 다른 C와 같이 기본적으로 예약되어 있는 키워드는 사용할 수 없다.

이를 통해 하나의 간단한 실습을 하나 해보자. 규칙을 적용하려는 대상은 바로 UPX로 패킹되어 있는 파일로, UPX의 경우 .code 섹션과 .data 섹션 등 섹션의 내용을 UPX 1 섹션에 압축한다. 이렇게 압축된 내용은 실행되면서 메모리에서 할당된 UPX 0 섹션의 주소에 압축을 풀어 본래의 내용을 실행한다. 따라서 "UPX0"라는 문자열과 "UPX1"이라는 문자열이 포함되어 있는지 확인해보자. 문자열의 여부를 확인하기 위해서는 "strings"를 사용하여야 하며 이는 아래의 그림을 보자.

규칙 "UPX_rule"을 선언하고 strings를 통해 $upx0와 $upx1을 선언해 각 UPX N 섹션의 여부 확인을 위한 문자열을 지정한다. 그 후 condition을 통해 $upx0을 만족하는 동시에 $upx1을 만족하는지 확인하며 만약 둘 중 하나라도 존재하지 않을 경우 False가 된다.

위 규칙을 사용하여 두 개의 파일에 관하여 확인해보았다. Yara-python으로 사용했기에 Python을 실행 후 Yara 모듈을 Import 해준다. 그 후 rules라는 변수에 규칙을 컴파일해주었고, 각 파일이 매칭 되는지 확인하기 위해 match()를 사용하였다. 결과를 확인해보면 UPX 패킹이 되어 있는 파일의 경우 규칙의 이름이 반환되었으며, UPX 패킹이 되어 있지 않은 파일의 경우 아무것도 반환되지 않았다.
이러한 과정을 통해 Yara의 기본적인 사용방법에 대하여 알아보았다. 지금의 예제는 빙산의 일각에 불과하며 Yara를 통해 더 많은 조건을 확인할 수가 있다. 많은 조건이 있지만 본 문서에서는 Strings에 해당하는 문자열과 바이너리를 통한 탐지에 정규표현식의 활용까지에 대하여 알아볼 것이다.
2. String 탐지
텍스트 문자열은 ASCII 인코딩, 대소문자를 구분하는 문자열을 표현하는 가장 간단한 방법으로 " " 사이에 텍스트를 넣어주면 된다. 여기서 만약 대소문자를 구분하지 않으려면 해당 " "뒤에 nocase 설정을 추가해주면 된다. 예를 들어 위에서 $upx0 = "UPX0"라 되어 있는 것을 $upx0 = "UPX0" nocase로 nocase를 추가하면 $upx0은 "UPX0"뿐만 아니라 "upx0", "Upx0", "uPx0" 등도 일치하게 된다.

다음으로 wide 설정은 2 바이트를 한 글자로 읽는 인코딩에 대하여 문자열을 검색할 때 사용할 수 있다. 대표적으로 Unicode가 있으며 $MFT 파일의 내용을 보면 $FILE_NAME에 존재하고 있는 파일의 이름이 2 바이트씩 읽어야 함을 알 수가 있다. 만약 "UPX0"라는 문자열이 아래와 같이 2 바이트씩으로 읽어야 할 때, wide 설정을 추가해주면 된다. 단, Wide와 ASCII 형태 모두 검색하고자 할 경우 wide ascii 설정을 해주면 된다.

마지막으로 fullword 설정에 대하여 알아보자. fullword 설정을 할 경우 숫자나 문자가 올 경우 이를 구분하게 된다. 예를 들어 "UPX0"라는 단어가 "123UPX0123"이나 "aUPX0", "UPX01" 등이 나올 경우 이는 거짓이 된다. 이에 반해 "...UPX0..."이나 "_UPX0_", " UPX0 " 등은 참이 된다.

이렇게 문자열에서 줄 수 있는 설정들에 대하여 알아보았다. 이를 위 그림처럼 규칙을 생성했을 경우 Unicode형태로 되어 있는 "UPX0", "UPX1"를 모두 읽는 것을 확인할 수가 있다. 이러한 설정은 같이 사용될 때 더욱 유연하게 사용될 수 있다.
3. Binary 탐지
16진수 문자열은 { } 사이에 Hex 값을 입력하는 형태로 입력해야 하며, Wild-cards, Jumps 그리고 Alternatives라는 세 가지 구조를 허용한다. 입력하고자 하는 16진수 값 중 모르거나 어떠한 바이트가 있더라도 상관이 없을 경우 Wild-Cards를 사용할 수가 있는데, wild-cards는 물음표(?)를 통해 바이트를 대체하여 나타낼 수가 있다. 아래의 그림을 보자.

Hex 값을 나타내는 규칙을 생성하며 "??"를 통해 Wild Cards를 사용하는 것을 확인할 수가 있다. 이러한 규칙을 위 Text에서 사용한 UPX0, UPX1가 존재하고 있는 파일에 적용하면 규칙에 부합한다는 결과를 얻을 수 있다. 여기서 한 바이트 "??" 뿐만 아니라 "?8"과 같이 한 바이트의 두 자릿수 중 한 자리에만 적용할 수도 있다.
하지만 만약 악성코드가 특정 시그니처 사이에 사용자의 계정이 존재할 경우, 사용자 계정의 길이는 개인마다 다르다. 이러한 경우 규칙을 제작하는 사람의 입장에서는 번거롭지만, Hex의 Jumps 기능을 통해 간편하게 규칙을 생성할 수 있다.

위 규칙과 같이 "name:....UPX"에서 "...."에 사용자의 계정이 존재할 경우 이에 관해선 확인할 수 없으므로 [n-m]의 형태를 통해 Jumps를 사용할 수 있다. n글자에서 m글자까지 무작위 하게 16진수가 올 수 있는데, 이는 "name:Kali-KMUPX", "name:SecurityUPX" 등 4글자에서 10글자 사이의 무작위 바이트를 허용한다. Jumps는 최대 [0-255]까지 허용하며 너무 범위가 크게 설정되어 있는 경우 성능의 저하를 초래할 수 있으므로 적절한 범위를 설정해야 한다.
이제 16진수를 나타낼 때 사용할 수 있는 Alternatives에 대하여 알아보자. Alternatives는 "A | B"로 나타내며, 이는 일반적인 프로그래밍 언어에서 사용하는 바와 같이 '또는'을 의미한다. 예를 들어 { AA BB (11|22) CC DD }로 설정할 경우, { AA BB 11 CC DD }와 { AA BB 22 CC DD } 둘 다 규칙에 부합된다. 하나의 글자가 아니라 여러 글자를 같이 적용할 수 있는데, { (AA BB CC | DD) FF }라 되어 있을 경우 {AA BB CC FF}와 {DD FF}가 조건에 부합된다. UPX를 예로 들어보자.

UPX 패킹의 경우 UPX0와 UPX1이라는 문자열을 발견할 수 있지만, UPX2는 존재하지 않는다. 따라서 위와 같이 "UPX(1|2)"로 규칙을 설정할 때, "UPX1" 또는 "UPX2" 둘 중 하나인 "UPX1"에 부합되므로 참이 된다. 만약 더 긴 문자열이나 불규칙적일 경우 두 바이트나 그 이상으로 (11 22 33 | AA)와 같이 Alternatives를 활용할 수도 있다. 마지막으로 이러한 기능들을 복합적으로 사용한 아래의 규칙을 보자.

위 그림과 같이 이러한 세 가지 기능은 같이 사용될 수가 있다. $a에는 "U"로 시작하며 그 사이에 1~6글자의 바이트가 무작위 하게 올 수 있으며 마지막에 "0"이 있는지 확인하는 것이다. $b의 경우 WildCards로 시작하여 마지막에 "0x3?"를 나타내므로 ASCII 글자인 0x30(0)와 0x31(1) 둘 다 올 수가 있다. 이렇게 기능들을 같이 사용하므로 훨씬 유연한 규칙을 생성할 수가 있다.
4. Regex 활용
정규표현식이란 특정한 규칙을 가진 문자열의 집합을 표현할 때 사용하는 '형식 언어'이다. Yara에서는 특정 문자열이나 바이너리뿐만 아니라 정규표현식 또한 사용할 수 있기에 이를 이해하고 있는 것은 Yara를 더 효율적으로 활용할 수 있게 한다. 우선 정규표현식에 대해 기초적인 개념을 설명한 뒤, Yara에서의 활용을 보자.

위 표는 정규표현식에서 사용할 수 있는 문법들에 대해 정리한 것이다. 이를 참고하여 몇 가지 문법을 직접 사용해보자. 악성코드와 관련해서 가끔 하드 코딩되어 있는 경우가 있다. 이러한 하드 코딩되어있는 문자열의 경우 주로 특정 사이트와의 연결을 위한 도메인 주소나 IP주소를 가지고 있는 경우가 있는데, 정규 표현식의 이해를 돕고자 이를 예제로 간단하게 구현해보자.
IP Address
IP의 경우 x.x.x.x와 같이 세 개의 '.'과 네 개의 숫자들로 구성되어 있다. 이를 정규표현식으로 구현하기 위해서는 숫자들의 집합과 '.'을 표현할 수 있어야 한다. 정규표현식에서 문자들의 집합은 '[ ]'으로 표현할 수가 있으며, 이를 통해 숫자를 나타내면 0부터 9까지 매칭 되어야 하므로 '[0-9]'가 된다. 하지만 간단하게 '\d'를 통해서도 숫자를 나타낼 수가 있다. 따라서 이를 통해 나타내면 "\d\.\d\.\d.\d"로 "숫자.숫자.숫자.숫자"의 형태가 된다.
하지만 IP 주소의 경우 한 자리마다 1 Byte로 최대 255까지 표현할 수 있지만 위의 표현은 한 글자씩만 해당한다. 따라서 이는 IP 주소로 나오는 숫자가 한 글자에서 세 글자까지 읽을 수 있도록 수정해야 하며, 이를 정규표현식으로 나타내기 위해서는 최소 n 개에서 최대 m 개 까지 반복됨을 나타내는 {n, m}을 사용하면 된다.
따라서 "\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}"과 같이 나타낼 수가 있다. 이를 그룹 '( )'으로 묶어 더 간략히 표현할 수 있으며, 이를 표현하면 "(\d{1,3}\.){3}\d{1,3}"이다.

Domain Name
특정 사이트에서 파일을 다운로드하거나 연결을 할 때 보통 도메인 주소가 포함되는 경우가 많다. 간단하게 구현해보며 이해하는 것이 목적이므로 "http://xxxx.xxxx.xxx"를 기준으로 해보자. 우선 http나 https라는 단어가 있을 경우 이를 통해 도메인 주소를 얻을 수가 있다.
우선 http와 https에서 공통적으로 'http'는 포함되므로 "http"를 입력한 뒤 '?'를 통해 's'를 's'가 없거나 하나 있을 경우에만 매칭 하는 결과를 얻을 수가 있다. 이를 통해 나타내면 "https?:"가 된다. 여기서 뒤의 도메인 주소는 공백이 아닌 문자가 오기 때문에 "\S"를 입력해주고 반복된 것 또한 포함하는 "+"를 입력해준다. 최종적으로 나타내면 "https:?\S+"가 된다.

이렇게 정규표현식에 대하여 간략히 알아보았다. 정규표현식에 대한 꾸준한 연습을 통해 이후 좀 더 정확한 표현식을 만드는 것은 중요하다. 실제 안티바이러스 제품의 경우 특정한 패턴을 통해 엔진에 등록되었을 때, 해당 패턴이 오류를 범하고 있어 정상 파일을 감염 파일로 간주하게 될 경우 큰 피해를 보게 된다.
In Yara
Yara에서 정규표현식을 표현하기 위해서는 "/Regex/"와 같이 두 개의 슬래시(/) 안에 정규 표현식을 사용하여야 한다. 정규표현식에선 String 탐지에서 사용할 수 있었던 'nocase', 'wide', 'ascii', 'fullword'의 기능을 사용할 수 있다. 아래의 그림을 보자.

문자열에 정규식을 사용하면서 'wide' 설정을 해주었다. 이 경우 A에서 Z까지의 문자가 3개 온 뒤 '0'이나 '1'이 오는 경우를 뜻하며 마지막에 wide를 설정해주므로 Unicode 문자열을 읽을 수 있게 된다. 따라서 "UPX0"나 "UPX1"은 조건에 부합되지만, 그 외에 "AAA0"이나 "FFF1" 등도 조건에 부합될 수 있어 오탐이 증가할 수 있다. 여기선 쉬운 이해를 위해 명확하지 않은 규칙과 예제를 사용하였지만, 정규표현식의 경우 특정 패턴을 매칭 시키는 데 있어 유용하다는 것은 명확한 사실이다.
5. Practice
이렇게 Yara를 통한 Strings에 대하여 살펴보았다. 마지막으로 학습한 내용을 정리해보고자 Python을 통한 실습을 해보자. 실습에 사용한 파일은 리버싱을 접해본 사람은 모두 알만한 Abex's CrackMe 01과 UPX이다. 대상 파일인 crackme01.exe가 UPX로 패킹되어 있는지 찾는 것이다. 이를 위해 2개의 코드를 작성하였는데, 우선 UPX 패킹 여부와 CrackMe01.exe인지 확인하기 위한 코드와 이러한 규칙을 적용시키기 위한 실행파일이다. 우선 제작한 규칙을 먼저 살펴보자.

위의 코드와 같이 "UPX_rule"이라는 규칙과 함께 "CrackMe01"이라는 규칙을 생성하였다. UPX_rule을 먼저 보면 UPX0 섹션과 UPX1 섹션에 지정된 문자열을 탐지하기 위한 변수 두 개와 두 변수가 모두 참이어야 규칙에 부합된다. 다음으로 CrackMe01의 경우 해당 파일에 하드 코딩되어 있는 세 가지 문자열을 각 변수로 선언하고 이 셋 중 하나라도 부합되면 참이 되도록 하였다. 이제 이러한 규칙을 실행시키기 위한 Python 코드를 작성해보자.
코드에 대한 자세한 설명은 생략하고, 몇 가지에 대해서만 설명하겠다. 규칙은 파일뿐만 아니라 프로세스에도 적용할 수 있으며 이 경우 rules.match(file)이 아닌 rules.match(pid=PID)와 같이 입력해야 한다. 따라서 -r 옵션을 통해 규칙 파일을 지정해주고, -d나 -p 옵션을 사용하여 파일이 존재하고 있는 폴더와 PID를 지정해줄 수 있다. 실습을 통해 두 경우 모두 확인해보자.

위 그림은 -d 옵션을 통해 경로를 여러 exe파일이 모여 있는 경로를 지정했다. 출력된 결과를 확인해보면 UPX 패킹으로 확인되는 것이 3개, CrackMe01으로 확인되는 것이 2개, 두 조건 모두 만족하는 것은 01.exe 하나라는 것을 확인할 수 있다. 다음으로 -p 옵션을 확인해보자.

출력 결과를 확인하면 PID 11504는 CrackMe01이며, PID 8664는 UPX패킹과 함께 CrackMe01의 조건을 만족한다. 실제로 PID 11504는 위의 Reverse_L01.exe이며, PID 8664는 01.exe로 두 조건을 모두 만족한다.
이처럼 실제 대상 파일들을 하나의 폴더에 모아놓은 뒤 yara를 적용하면 빠르게 대상 파일들을 구분할 수 있게 된다. 하지만 실제 Yara를 사용함에 있어 사용할 규칙은 엄격한 기준이 있어야 하며, 만약 빈약한 기준을 가지고 분류할 경우 오탐이나 미탐이 발생할 수 있기에 유의하여야 한다.
Reference
[+] 사이트
- http://hackganz.blogspot.kr/
- http://chogar.blog.me/80182473714
- http://www.dailysecu.co.kr/news_view.php?article_id=4776
- http://john09.tistory.com/121
- https://plusvic.github.io/yara/
- http://yara.readthedocs.org/en/v3.4.0/writingrules.html
- https://ko.wikipedia.org/wiki/정규_표현식
[+] 문서
- YARA_1.6_Korean_Users_Manual.pdf
- #WI-13-024.pdf(YARA를 이용한 악성코드 시그니처 확인)
'Reversing > Theory' 카테고리의 다른 글
| ClamAV & PEiD to Yara Rules (1) | 2016.03.11 |
|---|---|
| Yara 규칙 제작 & Python (1) | 2016.03.07 |
| 악성코드 분류 (0) | 2016.03.03 |
| 악성코드 분석 방법 (0) | 2016.02.26 |
| 악성코드 선호 경로 (0) | 2015.09.27 |






 Ransomware_Micro.pdf
Ransomware_Micro.pdf








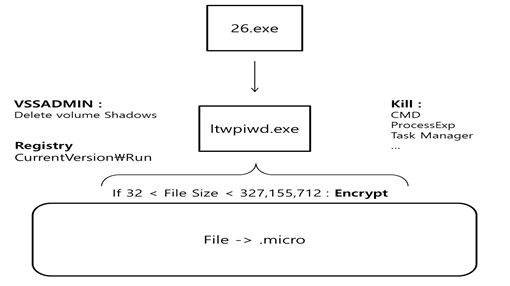
 추출한 프로세스를 IDA를 통해 분석을 진행하였다. 해당 프로세스에서는 0041F3E0에 주요 함수들이 있는 것으로 확인된다. 해당 부분의 앞부분에 SHGetFolderPath API를 통해 여러 폴더의 경로를 구해오는 것을 확인할 수가 있다.
추출한 프로세스를 IDA를 통해 분석을 진행하였다. 해당 프로세스에서는 0041F3E0에 주요 함수들이 있는 것으로 확인된다. 해당 부분의 앞부분에 SHGetFolderPath API를 통해 여러 폴더의 경로를 구해오는 것을 확인할 수가 있다.
 부분에 인자로 사용되는 명령어는 위에서 언급했던 vssadmin 명령어이다. 이렇게 vssadmin이 스레드를 통해 진행되는 것이다.
부분에 인자로 사용되는 명령어는 위에서 언급했던 vssadmin 명령어이다. 이렇게 vssadmin이 스레드를 통해 진행되는 것이다.































