

Web Security
'웹' 이라는 것은 하나의 시스템과 다른 하나의 시스템 간의 통신을 위한 프로토콜을 만들어 사용했다. 하지만 회사마다 서로 다른 통신프로토콜로 인하여 다른회사와는 통신을 할수가 없었다. 그리고 이를 해결하기 위해 하나의 프로토콜을 해석한 후 다른 프로토콜로 바꾸어 다른 시스템으로 전송해주는 장치인 GateWay를 개발했다.
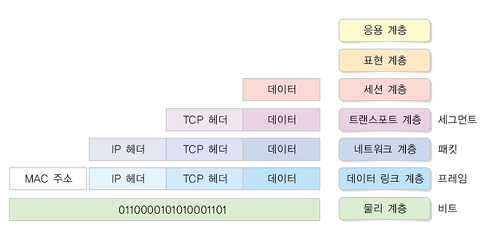
'웹'의 정식명칭 명칭은 World Wide Web이다. 현재 웹문서로 가장 흔히 쓰이는 HTML(Hyper Text Markup Language)은 Hyper Text를 효과적으로 전달하기 위한 스크립트 언어이다.
HTTP에 대한 이해 //Hyper Text Transfer Protocol
웹에서는 FTP, Telnet, HTTP, SMTP, POP등 여러 프로토콜이 쓰이며, 그 중에서 HTTP이 가장 흔히 쓰인다. HTTP를 이용하면 사용자는 다양한 응용 프로그램에 접근할수가 있다.
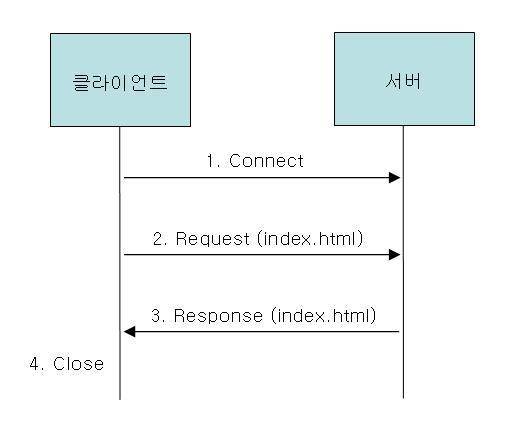
<HTTP Protocol>

1.먼저 클라이언트가 웹브라우저를 이용해 서버에 연결을 요청하면, 연결 요청을 받은 서버는 클라이언트에 대해 서비스를 준비한다. 서버가 준비상태가 된다.
2.클라이언트는 읽고자 하는 문서를 서버에 요청한다.
3.서버는 웹 문서중 클라이언트가 요청한 문서를 클라이언트에 전송한다.
4.연결을 끊는다.
하지만 이러한 Connect 과정을 반복해서 거쳐야 했기 떄문에 무척 비효율적이고 오래 사용되지 못했다. 하지만 1.0 버전 부터는 한번의 Connect 후에 Request와 Response를 반복할수 있게 되었다.
<HTTP Request>
HTTP Request는 웹서버에 데이터를 요청하거나 전송할때 보내는 패킷이다.
GET 방식
GET방식은 가장 일반적인 HTTP Request 형태로 웹 브라우저에 다음과 같은 요청 데이터에 대한 인수를 URL 을 통해 전송한다. www.wishfree.or.kr/list.php?page=1&search=test
GET방식에서는 각 이름과 값을 &로 결합하며 글자 수를 255자로 제한한다. 하지만 GET 방식은 데이터가 주소 입력란에 표시되기때문에, 최소한의 보안도 유지되지 않는, 보안에 매우 취약한 방식이다.
POST 방식
POST 방식은 URL에 요청 데이터를 기록하지 않고 HTTP 헤더에 데이터를 전송하기 떄문에 GET방식과 같은 &과 같은 부분이 존재하지 않는다. 하지만 상댖거으로 처리속도가 느리지만 URL을 통해 인수값을 전달하지 않기에 다른 이가 링크를 통해 해당 페이지를 볼수 없다는 면에서 최소한의 보안성은 갖추고 있다.
<HTTP Response>
HTTP Response는 클라이언트의 HTTP Request에 대한 응답 패킷이다.
웹 서비스에 대한 이해
웹 언어는 HTML, JavaScript, Visual Basic Script 와 같이 정적인 서비스를 제공하는 언어와 ASP, JSP, PHP 등과 같이 동적인 서비스를 제공하는 언어로 나눌 수 있다.
<HTML>
HTML은 가장 단순한 형태의 웹언어이다. 웹 서버에 HTML 문서를 저장하고 있다가 클라이언트가 특정 HTML 페이지를 요청하면 해당 HTML 문서를 클라이언트로 전송한다. 그러면 클라이언트는 이 웹페이지를 해석하여 웹 브라우저에 표현해주는데 이런 웹페이지를 정적인(Static) 웹 페이지라 한다.
<SSS>
기능상 한계가 많은 정적인 웹페이지 대신 좀더 동적인(Dynamic) 웹 페이지를 제공 할수 있는 PHP, ASP, JSP 와 같은 언어가 개발이 되었다.
ASP나 JSP와 같은 동적인 페이지를 제공하는 스크립트를 SSS(Server Side Script)라 한다. ASP의 경우 DLL이나 OCX 같은 파일을 이용하고 JSP의 경우 서블릿을 이용해 요청을 처리한다.
<CSS>
웹서비스에 이용되는 스크립트에는 자바스크립트나 비베스크립트 등이 있다. 이들은 서버가 아닌 클라이언트 측의 웹 브라우저에 의해 해석되고 적용되는데, 이를 CSS(Client Side Script>라 한다.
CSS는 서버가 아닌 웹 브라우저에서 해석되어 화면에 적용되기 떄문에 웹서버의 부담을 줄여주면서도 다양한 기능을 수행할수가 있다.
웹 해킹에 대한 이해
웹 해킹은 웹사이트의 구조와 동작 원리를 이해하는 것에서부터 시작한다. 기본적으로 사용되는 것이 웹스캔, 웹프록시를 이용한 패킷분석 구글해킹 등인데, 이는 웹해킹에 소요되는 대부분의 시간을 차지할 만큼 중요한 과정이다.
<웹 취약저 스캐너를 통한 정보 수집>
웹 취약점 스캐너를 통한 정보수집은 빠른 시간내에 다양한 접속 시도를 수행할수 있다는 장점이 있지만, 웹구조를 파악하고 취약점을 수집하기가 쉽지 않다는 단점이 있다. 각 페이지의 링크정보를 따라가는 것이므로 웹페이지에서 링크로 제공하지 않는 페이지는 구조 분석이 어렵다.
<웹 프록시를 통한 취약점 분석>
웹의 구조를 파악하거나 취약점을 점검할떄, 혹은 웹 해킹을 할떄는 웹 프록시라는 툴을 사용한다. 웹 프록시는 클라이언트에 설치되며 클라이언트의 통제를 받는다. 즉 클라이언트가 웹 서버와 웹 브라우저 간에 전달되는 모든 HTT[ 패킷을 웹 프록시를 통해서 확인하면서 수정하는 것이 가능하다.
<구글 해킹을 통한 정보 수집>
정보를 수집하기위해서는 검색 엔진을 이용하면 유용하다. 그 중에서도 구글은 다양한 고급 검색기능을 지원하기에 많은 정보를 접할수 있다.
site: 특정 사이트만을 집중적으로 선정해서 검색할떄 유용하다. 아래 검색어는 naver.com 도메인이 있는 페이지에서 admin 문자열을 찾으라는 의미이다. site:naver.com admin
filetype : 특정 파일 유형에 대해 검색할떄 사용한다. filetype:txt passwd
intitle : 페이지의 제목에 검색하는 문자가 들어있는 사이트를 찾는 기능으로 디렉터리 리스팅 취약점이 존재하는 사이트를 쉽게 찾을수 있기 떄문에 정보를 수집할떄 아주 유용하다. 아래 검색어를 입력하면 수많은 사이트의 디렉터리 리스팅을 확인할수 있다. intitleindex.of admin
검색엔진의 검색을 피하는 방법 : 웹서버의 홈 디렉터리에 robots.txt 파일을 만들어 검색 할 수 없게 만드는 것이다.
웹의 주요 취약점 10가지
1.명령 삽입 취약점
클라이언트의 요청을처리하기 위해 전송받는 인수에는 특정명령을 실행할수 있는 코드가 포함되는 경우가 있다. 명령 삽입공격은 웹서버와 연동되는 데이터 베이스에 임의의 SQL 명령을 실행하여 데이터를 수집한다.
데이터베이스에 SQL 삽입공격을 위해서는 인증이 필요하다 이를 위해서는 어떤 수단을 SQL의 결과값에 NULL이 나오지 않게, 즉 출력값이 사용자 ID가 되도록하면 로그인에 성공할수있다. 이를 위해서 자주 사용되는 방법으로는 SQL문에서 WHERE로 입력되는 조건문을 항상 참으로 만드는 방법이 있다. 바로 조건값에 'or' '='을 입력하는 것이다.
ID : 'or''=' SELECT user_id FROM member WHERE
Passwd : 'or''=' user_id = ''or''='' AND password = ''or ''=''
SQL 삽입공격에 사용되는 SQL문은 무엇이라도 SQL 삽입 공격에 사용될수 있다.
2. XSS 취약점
XSS(Cross Site Scripting)은 공격자에 의해 작성된 스크립트가 다른 사용자에게 전달되는 것이다.

주로 임의의 XSS 취약점이 존재하는 서버에 XSS코드를 작성하여 저장한다. 일반적으로 공격자는 임의의 사용자 또는 특정인이 이용하는 게시판을 이용한다.
3. 취약한 인증 및 세션 관리
취약한패스워드 설정 :취약한 인증의 가장 기본적인 문제점은 패스워드 설정
사용자 측 데이터를 이용한 인증 : 세션 인증 값을 정상적으로 받은 후 UserNo값만 변경함으로써 다른 계정으로 로그인 한 것처럼 웹서비스를 이용할수 있게 된다.
4. 직접 객체 참조
직접객체 참조는 파일, 디렉터리, 데이터베이스 키와 같이 내부적ㅇ로 구현된 객체에 대한 참조가 노출될떄 발생
- 디렉터리 검색
디렉터리 탐색은 웰브라우저에서 확인 가능한 경로의 상위로 탐색하여 특정시스템 파일을 다운로드하는 공격방법이다.
예를 들어 게시판등에서 첨부파일을 다운받을때 다음과 같이 down.jsp 형태의 SSS를 주로 사용한다.
www.kali-km.com/board/down.jsp?filename=사업계획.hwp
위와 같이 정상적인 다운로드 페이지를 이용해 다른 파일의 다운로드를 요청하면 어떻게 될까?
www.kali-km.com/board/down.jsp?filename=..//list.jsp
이와 같이 공격자가 상위로 올라가 특정 파일을 열람 할 수 있으므로 ..와 /문자를 필터링해야한다.
- 파일업로드 제한부재
클라이언트에서 서버측으로 임의의 파일을 보낼수 있는 취약점은 웹서버가 가지는 가장 치명적인 취약점이다. 공격자는 웹서버에 악의적이 파일을 전송하므로 통해 웹해킹의 최종목표인 리버스텔넷과 같은 웹서버의 통제권을 얻기위해 반드시 성공해야하는 작업이다. 이떄 가장 일반적인 형태는 게시판을 이용하며 첨부파일로 업로드 하는 악성코드는 대부분 웹쉘이다.
- 리버스텔넷(Reverse Telnet)
리버스텔넷 기술은 웹해킹을 통해 시스템의 권한을 획득한 후 해당 시스템에 텔넷과 같이 직접 명령을 입력하고 확인할수 있는 쉘을 획득하기 위한 방법으로 방화벽이 존재하는 시스템을 공격할떄 자주 사용된다.
심화된 공격을 하기위해서는 텔넷과 유사한 접근권한을 획득하는 것이 매우 중요한데, 이떄 리버스 텔넷이 유용하다.
방화벽에서 인바운드정책(외부에서 방화벽 내부로 들어오는 패킷에 대한 정책)은 80번 포트외에 필요한 포트만 빼고 다 막아 놓지만 아웃바운드정책(내부에서 욉로 나갈떄에 대한 정책)은 별다른 필터링을 수행하지 않는 경우가 많다.
웹서버에서 공격자 PC로 텔넷 연결을 허용하고 있는 상황을 공격자가 이용하는 것이 바로 리버스 텔넷이다. 하지만 그전에 웹서버에서 권한을 획득해야하며, 이를 위해 보통 파일업로드 공격을 이용하며 웹 쉘의 업로드를 통해 시스템에 명령을 입력할수 있는 명령창을 얻는 것이다. 리버스 텔넷을 위한 툴을 업로드하는데 보통 nc(netcat)라는 툴을 많이 사용한다.
리버스 텔넷을 막기위해서는 파일업로드를 먼저 막아야한다. 그리고 exe나 com 같은 실행파일의 업로드도 막아야한다. 또한 외부에서 내부로의 접속뿐만 아니라 내부에서 외부로의 불필요한 접속도 방화벽으로 막는 것이 좋다.
5. CSRF 취약점 (Cross Site Request Forgery)
CSRF는 특정 사용자를 대상으로 하지 않고, 불특정 다수를 대상으로 로그인된 사용자가 자신의 의지와는 무관하게 공격자가 위도한 행위를 하게 만드는 공격이다. CSRF는 기본적으로는 XSS 공격과 매우 유사하며 이의 발전된 형태라 보기도한다.
XSS는 악성스크립트가 클라이언트에서 실행되는데 반해, CSRF 공격은 사용자가 악성스크립트를 서버에 요청한다는 차이가 있다.
6. 보안 설정 취약점
- 디렉터리 리스팅
디렉터리 리스팅은 웹브라우저에서 웹서버의 특정 디렉터리를 열면 그 디렉터리에 있는 파일과 목록이 모두 나열되는 것을 의미한다. 취약점으로 인한 경우에는 www.kali-km.com/%3f.jsp 와 같이 간단한 공격 코드로도 디렉터리 리스팅을 수행할수 있으므로 패치를 적용해야 한다.
- 벡업 및 임시 파일 존재
개발자들이 웹사이트를 개발하고 난 훙 웹서버에 백업 파일이나 임시 파일들을 삭제하지 않은채 방치하는 경우가 종종 있다. 흔히 login.asp 파일이 웹서버의 편집 프로그램이 자동으로 생성하는 login.asp.bak과 같은 형태로 남는 경우를 말한다.
- 주석 관리 미흡
일반적으로 프로그램의 주석은 개발자만 볼수 있으나, 웹 어플리케이션의 경우에는 웹 프록시를 통해 이용자도 볼수 있다.
7. 취약한 정보 저장 방식
최근 개인정보 유출사건이 많아지는 가운데 중요한 데이터를 보호하기 위하여 암호화 로직을 사용하고, 데이터 베이스 테이블 단위에서 암호화를 수행 하여야 한다.
8. URL 접근 제한 실패
URL 접근제한 실패는 관리자 페이지가 추측하기 쉬운 URL을 가지거나 인증이 필요한 페이지에 대한 인증 미처리로 인해 인증을 우회하여 접속할수 있는 취약점이다.
원래는 관리자로 로그인해야 관리자용 웹페이지에 접속할수 있는 것인데, 로그인 하지 않고도 특저 작업이 가능한 경우가 발생한다.
인증 우회를 막기위해서는 웹에 존재하는 중요 페이지에 세션값(쿠키)을 확인하도록 검증 로직을 입력해둬야 한다.
9. 인증 시 비암호화 채널 사용
인터넷 뱅킹과 같이 보안성이 중요한 시스템에서는 웹 트래픽을 암호화한다. 이떄 사용되는 암호화 알고리즘이 약하거나 암호화 하는 구조에 문제가 있다면 웹 트래픽은 복호화 되거나 위변조 될수 있다.
10. 부적절한 오류 처리
웹페이지의 경우 자동으로 다른페이지로 리다이렉트 하거나 포워드하는 경우가 종종 발생한다. 이떄 신뢰되지 않은 데이터를 사용하는 경우가 있는데, 적절한 확인절차가 없으면 공격자는 피해자를 피싱사이트나 악의적인 사이트로 리다이렉트 할 수 있고, 권한 없는 페이지의 접근을 위해 사용할수도 있다.
웹의 취약점 보완
1. 특수문자 필터링
웹의 취약점은 다양하지만 대부분 몇가지 보완을 통해 막을수가 있다. 가장 대표적인 것이 특수문자 필터링이다. 웹 해킹의 가장 기본적인 형태 중 하나가 인수 조작인데 인수 조작은 예외적인 실행을 유발 시키기 위해 일반적으로 특수문자를 포함하게 되어 있다.
2. 서버 측 통제 작용
파일 업로드 취약점이나 특수문자 필터링을 수행할떄 주의할점은 자바스크립트와 같은 CSS 기반의 언어로 필터링을 하면 안된다는 것이다. CSS 기반의 언어는 웹프록시를 통해 웹브라우저에 전달되기 떄문에 웹프록시를 통해 전달되는 과정에서 변조될 가능성이 있다.
따라서 CSS 기반의 언어로 필터링 할 경우 공격자가 필터링 로직만 파악하면 쉽게 필터링이 무력화 된다. 즉 필터링 로직은 ASP, JSP 등과같은 SSS로 필터링을 수행해야 한다.
3. 지속적인 세션 관리
URL 접근 제한 실패를 막기 위해서는 기본적으로 모든 웹페이지에 세션에 대한 인증을 수행해야 한다. 모든 웹페이지에 대해 일관성 있는 인증 로직을 적요하려면 기업단위에서 또는 웹 사이트 단위에서 세션 인증로직을 표준화 하고, 모든 웹페이지를 개발할떄 해당 표준을 준수하도록 해야한다.
'Study > Book' 카테고리의 다른 글
| 정보보안개론 0x06 (0) | 2015.01.23 |
|---|---|
| 정보보안개론 0x05 (0) | 2015.01.22 |
| 정보보안개론 0x04 (0) | 2015.01.21 |
| 정보보안개론 0x02 (0) | 2015.01.12 |
| 정보보안개론 0x01 (2) | 2015.01.11 |






 IDA_Pro_Shortcuts.pdf
IDA_Pro_Shortcuts.pdf


