PE구조의 이해.pdf
PE구조의 이해.pdf
개요
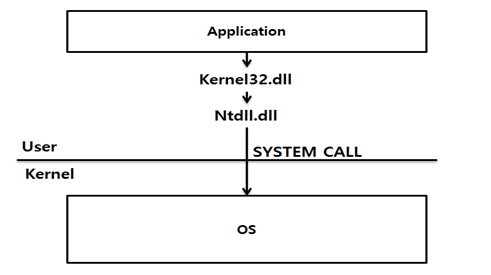
우리가 컴퓨터로 무엇인가 작업하기 위해서는 언제나 특정 프로그램을 실행시킨다. 이러한 실행 파일 또는 응용 프로그램이라 불리는 EXE 파일 말고도 프로그램 실행을 위한 DLL 파일도 프로그램 실행 시에 같이 물려 메모리 상에 로드된다. 이러한 EXE 파일 관련 DLL 파일들이 메모리 상에 로드되면서 비로소 프로그램이라는 것이 사용 가능하게 되고 이렇게 로드된 하나의 EXE와 여러 개의 관련 DLL들이 소위 운영체제론에서 이야기하는 하나의 프로세스를 구성하게 된다.

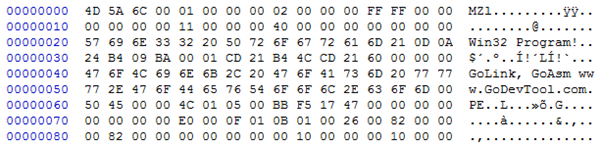
그림 1. HxD로 본 PE 구조
이러한 실행 파일들은 항상 MZ라는 식별 가능한 문자로 시작하는데 이는 무의미한 문자가 아니라 PE(Portable Executable)구조로 된 PE 파일들을 나타낸다. PE파일은 이름과 같이 플랫폼에 관계없이 Win32 운영체제가 돌아가는 시스템이면 어디서든 실행 가능하다는 의미를 지니고 있다. 따라서 우리는 이러한 PE파일의구조를 중점적으로 알아볼 것이다
PE 파일의 전체 구조
PE 파일의 전체적인 구조에 대하여 알아보자. PE 파일은 아래의 그림과 같은 형태로 "MZ"가 위치하고 있는 IMAGE_DOS_HEADER를 시작으로 프로그램의 많은 정보를 구조체 형태로 포함하고 있다. 도스 헤더의 경우 PE파일임을 구별할 수 있도록 시작 부분에 "MZ" Signature(4D5A)로 시작한다. 그 다음 도스 스텁이 나오는데 이는 필수적이지 않은 존재로 16 Bit 환경에서 출력될 문자열인 "This program cannot be run in DOS mode"라는 문자열 등을 포함하고 있다.

그림 2. 일반적인 PE 구조의 형태
그 다음 본격적인 "PE" Signature(5045)가 존재하고 있는 IMAGE_NT_HEADERS로 이 부분은 크게 IMAGE_FILE_HEADER와 IMAGE_OPTIONAL_HEADER 두 부분으로 나눌 수가 있다. FILE 헤더의 경우 PE 파일에 대한 파일 정보를 나타내고 OPTIONAL 헤더의 경우 PE 파일이 메모리에 로드될 때 필요한 모든 정보들을 담고 있다. OPTIONAL_HEADER 내에는 기본 필드들과 함께 주요 섹션들의 위치와 크기를 나타내는 IMAGE_DATA_DIRECTORY 구조체 배열을 담고 있다. 이에 대해선 추후에 더 자세히 설명할 것이다.

그림 3. PE View로 본 IMAGE_DATA_DIRECTORY
IMAGE_DATA_DIRECTORY를 끝으로 IMAGE_SECTION_HEADER가 여러 개 나오는데, 이는 섹션 테이블로 각 섹션의 위치와 크기 등의 정보를 포함하고 있다. MZ헤더부터 섹션 테이블까지 PE 파일 헤더라 하며, PE 헤더 뒷부분부터는 실제 코드나 데이터들이 성격에 맞게 각각의 섹션에 위치하고 있다.
PE 분석을 위한 개념 정리
PE 파일 구조를 분석하기 전에 알아야할 내용들에 대하여 언급할 것이다. RVA, Section, MMF, VSA에 대하여 알아보자.
RVA (Relative Virtual Address)
RVA는 상대적 가상 주소로 파일 Offset과는 다른 개념이다. Offset은 파일에서의 위치를 나타낼 때 사용하는 개념이지만 RVA는 가상 주소 공간 상의 위치를 나타낼 때 사용하는 개념으로 메모리 상에서의 PE의 시작 주소에 대한 오프셋으로 생각하면 된다. 그렇다면 메모리에서는 왜 Offset이나 VA가 아닌 RVA로 나타낼까?
이는 PE 파일이 지정된 베이스 위치(ImageBase)를 기준으로 로딩된다는 보장이 없기 때문이다. EXE 파일의 경우 일반적으로 파일이 지정된 위치에 로드된다. DLL의 경우 일반적으로 ImageBase 값이 0x1000000으로 설정되어 있지만 하나의 프로세스에는 여러 개의 DLL이 존재하고 있기 때문에 ImageBase를 기준으로 할 경우 중첩된다. 이러한 중첩을 방지하기 위해 DLL Relocation이 존재하고 있으며 이러한 이유로 인해 절대 주소가 아닌 상대 주소를 사용한다. 만약 ImageBase가 0x2000000이며 RVA 값이 0x1234라고 한다면 가상 주소의 값은 0x02001234이 되는 것이다.
Section
PE 파일에서 섹션은 PE가 가상 주소 공간에 로드된 다음 실제 내용을 담고 있는 블록들이다. 대표적인 내용으로는 명령어 코드와 데이터이며, 그 외에 실행에 관련된 여러 정보들이 섹션에 배치된다. 대표적으로 언급할만한 섹션들에 대하여 간단히 알아보자.
종류 | 이름 | 설명 |
코드 | .text | 프로그램을 실행하기 위한 코드를 담고 있는 섹션으로, 명령 포인터는 이 섹션 내에 존재하는 번지 값을 담게 된다. |
데이터 | .data | 초기화된 전역 변수들을 담고 있는 읽고 쓰기 가능한 섹션이다. |
.rdata | 읽기 전용 데이터 섹션으로 문자열 표현이나 C++/COM 가상 함수 테이블 등이 .rdata에 배치되는 항목 중의 하나이다. |
.bss | 초기화되지 않은전역 변수들을 위한 섹션이다. 실제 PE 파일 내에서는 존재하지만 가상 주소 공간에 매핑될 때에는 보통 .data 섹션에 병합되어 메모리 상에서는 따로 존재하지 않는다. |
Import API 정보 | .idata | 임포트 할 DLL과 그 API들에 대한 정보를 담고 있는 섹션이다. 대표적으로 IAT가 존재한다. |
.didat | 지연 로딩(Delay-Loading) 임포트 데이터를 위한 섹션으로 지연 로딩은 Windows 2000부터 지원되는 DLL 로딩의 한 방식으로 암시적인 방식과 명시적인 방식의 혼합이다. |
Export API 정보 | .edata | 익스포트 할 DLL과 그 API들에 대한 정보를 담고 있는 섹션이다. 보통 API나 변수를 익스포트 할 수 있는 경우는 DLL이기 때문에 DLL PE에 이 섹션이 존재한다. |
리소스 | .rsrc | 다이얼로그, 아이콘, 커서 등의 윈도우 APP 리소스 관련 데이터들이 이 섹션에 배치된다. |
재배치 정보 | .reloc | 실행 파일에 대한 기본 재배치 정보를 담고 있는 섹션이다. 재배치란 PE 이미지를 원하는 기본 주소에 로드하지 못하고 다른 주소에 로드했을 경우 코드 상에서의 관련 주소 참조에 대한 정보를 갱신해야 하는 경우를 말한다. 위에서 언급한 바와 같이 주로 DLL 파일에서 재배치가 일어난다. |
TLS | .tls | __declspec(thread) 지시어와 함께 선언되는 스레드 지역 저장소를 위한 섹션이다. 이 섹션에는 런타임이 필요로 하는 부가적인 변수나 __declspec(thread) 지시어에 의한 데이터의 초기 값을 포함한다. |
C++ 런타임 | .crt | C++ 런타임(CRT)을 지원하기 위해 추가된 섹션으로 정적 C++ 객체의 생성자와 소멸자를 호출할 때 이용되는 함수 포인터가 예이다. |
Short | .sdata | 전역 포인터에 상대적으로 주소 지정될 수 있는 읽고 쓰기 가능한 "Short" 데이터 섹션이다. IA-64 같은 전역 포인터 레지스터를 사용하는 플랫폼을 위해 사용된다. |
.srdata | .sdata에 들어갈 수 있는 데이터들의 읽기 전용 섹션이다. |
예외 정보 | .pdata | IMAGE_RUNTIME_FUNCTION_ENTRY 구조체의 배열을 가지며 예외 정보를 담고 있는 섹션이다. 이 섹션의 위치는 IMAGE_DIRECTORY_ENTRY_EXCEPTION 슬롯을 통해 알 수 있으며, Table-base exception handling을 사용하는 플랫폼에서 지원된다. 이를 지원하지 않는 유일한 플랫폼은 x86 계열의 CPU이다. |
디버깅 | .debug$S | OBJ파일에 존재하는 가변길이 코드뷰 심벌레코드의 스트림이다. |
.debug$T | OBJ파일에 존재하는 가변길이 코드뷰 심벌레코드의 스트림이다. |
.debug$P | 미리 컴파일된 헤더를 사용했을 때 OBJ 파일에만 존재한다. |
Directives | .drectve | OBJ 파일에만 존재하는 섹션으로 Directives란 링커 명령 라인을 통해 전달할 수 있는 ASCII 문자열을 말한다. |
그림 4. 대표적인 섹션의 종류
VAS (Virtual Address Space)
마지막으로 고려할 것은 파일로 존재하는 PE구조와 이것이 메모리에 올라올 때 주어지는 가상 주소 공간(VAS)에서의 PE 구조에 대한 관계이다. 이를 위해 MMF(Memory Mapped File)에 대하여 먼저 알아보자. 32비트 환경에서 프로세스는 4GB의 VAS를 갖는데, 이 가상 공간을 실제의 물리적인 기억 장치와 연결시켜 주는 것이 가상 메모리 관리자(Virtual Memory Manager, VMM)이다. 여기서 물리적 기억장치는 RAM 뿐만 아니라 하드디스크 상의 특정 파일(기본적으로는 PageFile.sys)을 포함한다. 이와 함께 페이징 기법을 통해 프로세스에게 실제로 4GB의 주소 공간을 가진 것처럼 사용할 수 있다.
페이징 파일과 RAM 그리고 VAS는 VMM에 의해 관리되며 프로세스에 속한 특정 스레드가 가상 주소 공간 내의 특정 번지에 접근하고자 할 때, VMM은 해당 번지의 페이지를 페이징 파일과 매핑시켜 준다. 매핑된 페이지는 접근 가능한 상태가 되며, 여기서 이러한 페이징은 반드시 PageFile.sys하고만 이루어져야 하는 것은 아니라 일반 파일을 메모리에 맵핑하여 이에 대해 페이징 할 수 있다. 이처럼 일반적인 파일이 PageFile.sys의 역할을대신하는 경우를 MMF라고 한다. 이제 MMF를 사용하기 위한 함수에 대하여 알아보자.
HANDLE CreateFileMapping(
HANDLE hFILE,
LPSECRITY_ATTRIBUTES lpAttributes,
DWORD flProtect,
DWORD dwMaximumSizeHigh,
DWORD dwMaximumSizeLow,
LPCTSTR lpName); |
그림 5. CreateFileMapping API
CreateFileMapping API는 운영체제에게 매핑을 수행할 파일의 물리 저장소를 알려주기 위한 API이다. 이를 통해 지정 파일을 파일 매핑 오브젝트와 연결시키며, 파일 매핑 오브젝트를 위한 충분한 물리 저장소가 존재한다는 것을 확인시킨다.
hFile의 경우 CreateFile()과 같은 API를 통해 얻은 파일의 핸들로 물리 저장소로 사용할 파일의 핸들을 주어야한다. flProtect는 MMF의 페이지 속성을 지정하는데 PAGE_READONLY, PAGE_READWRITE, PAGE_WRITECOPY와 같은 세 가지 보호 속성을 기본으로 가진다. 이 세 가지 보호 속성 외에 다섯 가지 메모리 매핑 파일만의 속성을 추가로 지정할 수 있다.
속성 | 설명 |
SEC_NOCACHE | 메모리 매핑 파일에 대한 캐싱을 수행하지 못하게 한다. |
SEC_IMAGE | 매핑한 파일이 PE파일 이미지임을 알려주므로 실행파일 실행 시 사용 |
SEC_RESERVE
SEC_COMMIT | 이 두개는 배타적으로 사용되어야 한다. 스파스 메모리 맵 파일과 관련이 있다. |
SEC_LARGE_PAGES | 큰 페이지 할당 기능과 관련 있다. |
그림 6. flProtect 항목
하지만 파일 매핑 오브젝트를 생성한다 하더라도, 시스템은 곧바로 프로세스의 주소 공간 상에 영역을 예약하지 않는다. 그렇기에 파일의 데이터에 접근하기 위한 영역을 프로세스 주소 공간 내에 확보해야 하며, 이 영역에 임의의 파일을 물리 저장소로 사용하기 위한 커밋 단계를 거쳐야 하며 이를 위해 사용하는 API가 바로 MapViewOfFile이다.
PVOID MapViewOfFile(
HANDLE hFileMappingObject,
DWORD dwDesiredAccess,
DWORD dwFileOffsetHigh,
DWORD dwFileOffsetLow,
DWORD dwNumberOfBytesToMap); |
그림 7. MapViewOfFile API
첫 번째 인자는 CreateFileMapping으로 얻은 핸들을 넘겨주면 되고 두 번째 인자에 사용할 수 있는 항목은 아래와 같다. 세 번째와 네 번째 인자의 경우 파일의 어디부터 매핑할 것인지 지정해주는 것으로 파일의 오프셋 값은 반드시 시스템의 할당 단위의 배수여야 한다. 마지막 인자의 경우 얼마만큼 해당할지 설정하는 것으로 값이 0일 경우 오프셋으로부터 파일의 끝까지 구성한다.
항목 | 설명 |
FILE_MAP_READ | CreateFileMapping에서 PAGE_READ_ONLY로 설정한 경우 |
FILE_MAP_WRITE | CreateFileMapping에서 PAGE_READWRITE로 설정한 경우 |
FILE_MAP_ALL_ACCESS | FILE_MAP_READ | FILE_MAP_WRITE | FILE_MAP_COPY와 같다. |
FILE_MAP_COPY | CreateFileMapping에서 PAGE_WRITECOPY로 설정한 경우로, 데이터를 쓰면 새로운 페이지가 생성된다. |
FILE_MAP_EXECUTE | 데이터를 코드로 수행할 수 있다. |
그림 8. dwDesiredAccess 항목
이렇게 MMF를 형성할 수 있으며 프로세스 주소 공간 내에 매핑된 데이터 파일을 더 이상 유지할 필요가 없다면 UnmapViewOfFile 함수를 호출하여 영역을 해제해 주어야 한다. 사용되는 인자는 하나뿐이며 해제할 영역의 주소를 넘겨주면 된다.
BOOL WINAPI UnmapViewOfFile(
_In_ LPCVOID lpBaseAddress); |
그림 9. UnmapViewOfFile API
마지막으로 이전에 얻어온 파일 오브젝트와 파일 매핑 오브젝트가 올바르게 반환이 이루어질 수 있도록 CloseHandle API를 호출해주어야 한다. 사용되는 인자는 역시 하나로 핸들을 넘겨주어야 한다.
BOOL WINAPI CloseHandle(
_In_ HANDLE hObject); |
그림 10. CloseHandle API
이렇게 MMF를 사용하는 방법에 대하여 알아보았다. 사실 이 MMF에 대하여 공부하며 어느 곳에 사용해야하는 것인지 의문을 가질 수가 있다. 이렇게 MMF에대하여 자세히 알아본 이유가 무엇일까? 바로 Windows는 EXE나 DLL 등의 실행 파일을 로드할 때 MMF를 이용한다. 즉, PE 파일을 페이징 파일로 복사하는 것이 아니라 그 파일 자체를 페이징 파일로 사용한다는 것이다.
<File>
00400000 4D 5A 6C 00 01 00 00 00 02 00 00 00 FF FF 00 00 MZl.........
00400010 00 00 00 00 11 00 00 00 40 00 00 00 00 00 00 00 .......@.......
00400020 57 69 6E 33 32 20 50 72 6F 67 72 61 6D 21 0D 0A Win32 Program!..
00400030 24 B4 09 BA 00 01 CD 21 B4 4C CD 21 60 00 00 00 $???퀽?`...
00400040 47 6F 4C 69 6E 6B 2C 20 47 6F 41 73 6D 20 77 77 GoLink, GoAsm ww
00400050 77 2E 47 6F 44 65 76 54 6F 6F 6C 2E 63 6F 6D 00 w.GoDevTool.com.
00400060 50 45 00 00 4C 01 05 00 BB F5 17 47 00 00 00 00 PE..L.새G.... |
<Process>
00000000 4D 5A 6C 00 01 00 00 00 02 00 00 00 FF FF 00 00 MZl.........
00000010 00 00 00 00 11 00 00 00 40 00 00 00 00 00 00 00 .......@.......
00000020 57 69 6E 33 32 20 50 72 6F 67 72 61 6D 21 0D 0A Win32 Program!..
00000030 24 B4 09 BA 00 01 CD 21 B4 4C CD 21 60 00 00 00 $???퀽?`...
00000040 47 6F 4C 69 6E 6B 2C 20 47 6F 41 73 6D 20 77 77 GoLink, GoAsm ww
00000050 77 2E 47 6F 44 65 76 54 6F 6F 6C 2E 63 6F 6D 00 w.GoDevTool.com.
00000060 50 45 00 00 4C 01 05 00 BB F5 17 47 00 00 00 00 PE..L.새G.... |
그림 11. 파일과 프로세스에서의 PE 시작점
위 두 개의 바이너리를 보자. 파일에서의 바이너리와 할당된 가상 주소에서의 바이너리가 주소만 다르지 내용은 같다는 것을 확인할 수 있다. 이는 해당파일 자체가 그대로 가상 주소 공간에 매핑된다는 것으로, EXE나 DLL 와 같은 PE 파일을 실행할 때 PE 파일 내에 정의된 바와 같이 가상 주소 공간에 매핑된다는 것이다. 지금까지 PE의 개략적인 구조와 RVA, Section, 그리고 PE와 MMF의 관계에 대해 알아보았다. 다음 장부터는 구체적으로 PE 파일에 대하여 알아보자.
IMAGE_DOS_HEADER & IMAGE_DOS_STUB
PE 파일에서 가장 처음으로 등장하는 영역은 바로 도스 헤더와 도스 스텁 영역이다. 도스 헤더에는 총 64 Bytes로 19개의 필드를 갖지만, 실제로 중요한 필드는 단 두 개뿐이다. e_magic 필드는 MZ 헤더의 시그니처가 존재하는 필드로 PE 파일이 맞는지 아닌지 체크할 때 사용되며, 이는 도스 헤더의 시작을 알리는 코드라 할 수 있다. e_lfanew 필드는 NT헤더의 시작 위치를 나타내는 값으로 해당 오프셋을 확인해보면 NT 헤더의 시그니처인 "PE"가 존재하고 있다.
typedef struct _IMAGE_DOS_HEADER {
WORD e_magic;
/* 00: MZ Header signature */
WORD e_cblp;
/* 02: Bytes on last page of file */
WORD e_cp;
/* 04: Pages in file */
WORD e_crlc; /* 06: Relocations */
WORD e_cparhdr;
/* 08: Size of header in paragraphs */
WORD e_minalloc;
/* 0a: Minimum extra paragraphs needed */
WORD e_maxalloc;
/* 0c: Maximum extra paragraphs needed */
WORD e_ss;
/* 0e: Initial (relative) SS value */
WORD e_sp; /* 10: Initial SP value */
WORD e_csum;
/* 12: Checksum */
WORD e_ip; /* 14: Initial IP value */
WORD e_cs; /* 16: Initial (relative) CS value */
WORD e_lfarlc;
/* 18: File address of relocation table */
WORD e_ovno;
/* 1a: Overlay number */
WORD e_res[4];
/* 1c: Reserved words */
WORD e_oemid; /* 24: OEM identifier (for e_oeminfo) */
WORD e_oeminfo; /* 26: OEM information; e_oemid specific */
WORD e_res2[10];
/* 28: Reserved words */
DWORD e_lfanew; /* 3c: Offset to extended header */
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER; |
그림 12. IMAGE_DOS_HEADER 구조체
IMAGE_DOS_STUB은 아래와 같은 형태를 띄고 있으며 큰 의미를 갖지 않는다. 아래의 표를 보면 식별 가능한 문자열이 존재하고 있는데 이는 MS-DOS나 윈도우 3.1에서 실행하게 되면 바로 이 문장을 출력한다. MS-DOS 스텁은 위 문장을 출력하기 위한 16비트 도스용 응용 프로그램이라 할 수 있다.
00400050 54 68 69 73 20 70 72 6F 67 72 61 6D 20 6D 75 73 This program mus
00400060 74 20 62 65 20 72 75 6E 20 75 6E 64 65 72 20 57 t be run under W
00400070 69 6E 33 32 0D 0A 24 37 00 00 00 00 00 00 00 00 in32..$7........ |
그림 13. 예제.exe의 IMAGE_DOS_STUB
이렇게 도스 헤더와 도스 스텁에 대하여 알아보았는데, 결국 이 두 구조체에서 필수적인 항목은 단 두개 뿐인 것이다. 다시 말해, 다른 필드의 항목들은 모두 NULL이 되어도 상관없다는 것이다. 한번 직접 코드를 비교해보자. 아래는 불필요한 항목들을 제거하지 않은 상태의 코드와 불필요한 항목들을 제거한 다음의 코드를 비교한 것이다.
<수정 전>
00000000 : 4D 5A 50 00 02 00 00 00 04 00 0F 00 FF FF 00 00 MZP.............
00000010 : B8 00 00 00 00 00 00 00 40 00 1A 00 00 00 00 00 ........@.......
00000020 : 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000030 : 00 00 00 00 00 00 00 00 00 00 00 00 00 01 00 00 ................
00000040 : BA 10 00 0E 1F B4 09 CD 21 B8 01 4C CD 21 90 90 ........!..L.!..
00000050 : 54 68 69 73 20 70 72 6F 67 72 61 6D 20 6D 75 73 This program mus
00000060 : 74 20 62 65 20 72 75 6E 20 75 6E 64 65 72 20 57 t be run under W
00000070 : 69 6E 33 32 0D 0A 24 37 00 00 00 00 00 00 00 00 in32..$7........ |
<수정 후>
00000000 : 4D 5A 00 00 00 00 00 00 00 00 00 00 00 00 00 00 MZ..............
00000010 : 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000020 : 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000030 : 00 00 00 00 00 00 00 00 00 00 00 00 00 01 00 00 ................
00000040 : 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000050 : 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000060 : 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000070 : 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ |
그림 14. 필수적이지 않은 요소 제거
코드를 이렇게 수정을 해도 프로그램이 정상적으로 구동되는 것을 확인할 수 있을 것이다. 각 필드 마다 의미를 가지고 있기는 하지만, PE 구조에서는 이러한 정보들이 존재하지 않더라도 정상적으로 구동하도록 되어있다.
IMAGE_NT_HEADER
IMAGE_DOS_HEADER의 e_lfanew 필드 값에 해당하는 위치에 IMAGE_NT_HEADER가 존재하고 있다. 해당 구조체에는 PE와 관련된 주요 필드들이 위치해 있다. 우선 해당 위치에는 PE Signature, IMAGE_FILE_HEADER, IMAGE_OPTIONAL_HEADER로 분류할 수 있다. 아래의 구조체를 확인해보자.
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature; /* "PE"\0\0 */ /* 0x00 */
IMAGE_FILE_HEADER FileHeader; /* 0x04 */
IMAGE_OPTIONAL_HEADER32 OptionalHeader; /* 0x18 */
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32; |
그림 15. IMAGE_NT_HEADER 구조체
IMAGE_FILE_HEADER
IMAGE_FILE_HEADER에는 해당 PE 파일과 관련된 내용이 존재하고 있는 20 Bytes로 구성된 구조체이다. 첫 번째 필드에는 CPU의 ID를 나타내는 것으로 세 가지 주요 타입은 다음과 같이 Intel 386의 경우 0x014C, Intel 64의 경우 0x200, AMD64의 경우 0x8664의 값을 갖는다. 두 번째 필드의 경우 본 파일에서 섹션의 수를 나타내는 것이며 세 번째 필드 TimeDataStamp는 파일이 OBJ 형식의 파일이면 컴파일러가, EXE나 DLL과 같은 PE 파일이라면 링커가 해당 파일을 만들어낸 시간을 의미한다.
PointerToSymbolTable의 경우 COFF 심벌의 파일 오프셋을 나타내는 것으로, 이 필드는 컴파일러에 의해 생성되는 OBJ 파일이나 디버그 모드로 만들어져 COFF 디버그 정보를 가진 PE 파일에서만 사용된다. 그 다음 NumberOfSybols는 PointerToSymbolTable 필드가 가리키는 COFF 심벌 테이블 내의 심벌 수를 나타낸다. IMAGE_FILE_HEADER 다음에는 IMAGE_OPTIONAL_HEADER가 이어서 나오는데 바로 해당 구조체의 크기를 나타내는 것이 SizeOfOptionalHeader 필드이다. 마지막으로 Chracteristics 필드는 해당 PE 파일에 대한 특정 정보를 나타내는 플래그로 주요 항목 몇 가지가 [그림 17]과 같다.
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER; |
그림 16. IMAGE_FILE_HEADER 구조체
매크로 명 | 값 | 의미 |
IMAGE_FILE_RELOCS_STRIPPED | 0x0001 | 현재 파일에 재배치 정보가 없다. |
IMAGE_FILE_EXECUTABLE_IMAGE | 0x0002 | 본 파일은 실행 파일 이미지이다. |
IMAGE_FILE_LINE_NUMS_STRIPPED | 0x0004 | 본 파일에 라인 정보가 없다. |
IMAGE_FILE_LOCAL_SYMS_STRIPPED | 0x0010 | OS로 하여금 적극적으로 워킹 셋을 정리할 수 있도록 한다. |
IMAGE_FILE_LARGE_ADDRESS_AWARE | 0x0020 | 응용프로그램이 2GB 이상의 가상 주소 번지를 제어할 수 있도록 한다. |
IMAGE_FILE_32BIT_MACHINE | 0x0100 | 본 PE는 32비트 워드 머신을 필요로 한다. |
IMAGE_FILE_DEBUG_STRIPPED | 0x0200 | 디버그 정보가 본 파일에 없고 .DBG 파일에 존재한다. |
IMAGE_FILE_REMOVABLE_RUN_FROM_SWAP | 0x0400 | PE이미지가 이동 가능 장치 위에 존재하면 고정 디스크 상의 스왑 파일로 카피해 실행한다. |
IMAGE_FILE_NET_RUN_FROM_SWAP | 0x0800 | PE이미지가 네트워크 상에 존재하면 고정 디스크 상의 스왑 파일로 카피해서 실행한다. |
IMAGE_FILE_DLL | 0x2000 | 본 파일은 동적 링크 라이브러리(DLL)파일이다. |
IMAGE_FILE_UP_SYSTEM_ONLY | 0x4000 | 본 파일은 하나의 프로세서만을 장착한 머신에서 실행된다. |
그림 17. Characteristics의 주요 PE 특성
IMAGE_OPTIONAL_HEADER
IMAGE_FILE_HEADER의 뒷부분에 나오는 IMAGE_OPTIONAL_HEADER 구조체에는 메모리에 올라갈 때 참조해야 할 주요한 필드들이 위치하고 있다. 해당 구조체는 총 224 Bytes의 크기를 갖으며 많은 필드가 위치해있다. 아래의 구조체를 보자.
typedef struct _IMAGE_OPTIONAL_HEADER {
/* Standard fields */
WORD Magic; /* 0x10b or 0x107 */ /* 0x00 */
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint; /* 0x10 */
DWORD BaseOfCode;
DWORD BaseOfData;
/* NT additional fields */
DWORD ImageBase;
DWORD SectionAlignment; /* 0x20 */
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion; /* 0x30 */
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum; /* 0x40 */
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve; /* 0x50 */
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
/* 0x60 */ /* 0xE0 */
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32; |
그림 18. IMAGE_OPTIONAL_HEADER 구조체
첫 번째 필드인 Magic은 IMAGE_OPTIONAL_HEADER를 나타내는 Signature로 32비트 PE의 경우 0x010B이고, 64비트 PE의 경우 0x020B, ROM 이미지 파일에 대해서는 0x0107의 값을 갖고 있는 것을 확인할 수 있다. MajorLinkerVersion과 MinorLinkVersion는 본 파일을 만들어낸 링커의 버전을 나타낸다. SizeOfCode의 경우 코드 섹션(.text) 섹션의 크기이며 SizeOfInitializedData, SizeOfUninitializedData의 경우 각각 코드 섹션을 제외한 "초기화된 데이터 섹션의 크기"와 "초기화되지 않은 데이터 섹션의 크기"를 나타낸다.
AddressOfEntryPoint는 로더가 실행을 개시할 주소를 나타낸다. 이 주소는 RVA로서 보통 .text 섹션 내의 특정 번지가 된다. 이 필드의 값은 프로그램이 처음으로 실행될 코드를 담고 있는 주소이다. 즉, 프로그램이 로드된 후 이 프로세스의 메인 스레드 문맥의 EIP 레지스터가 가질 수 있는 최초의 값이라 할 수 있다. BaseOfCode, BaseOfData의 경우 각각 첫 번째 코드 섹션이 시작되는 RVA, 데이터 섹션이 시작되는 RVA를 의미한다.
ImageBase 필드는 해당 PE가 가상 주소 공간에 매핑될 때 매핑시키고자 하는 메모리 상의 시작 주소이다. 일반적으로 EXE 파일의 ImageBase 값은 0x400000이며 DLL의 경우 0x1000000이지만, DLL의 경우 하나의 VAS에 여러 DLL이 존재할 수 있으므로 DLL Relocation을 필요로 하게 된다.
PE 파일은 섹션으로 나뉘어져 있는데 파일에서 섹션의 최소단위를 나타내는 것이 FileAlignment이며 메모리에서 섹션의 최소단위를 나타내는 것이 SectionAlignment이다. 각 섹션의 시작 주소는 언제나 각 필드의 배수가 되는 주소가 되도록 보장해야 한다.
MajorOperatingSystemVersion, MinorOperatingSystemVersion은 해당 PE를 실행하는데 필요한 운영체제의 최소 버전을 의미한다. MajorImageVersion과 MinorImageVersion은 유저가 정의 가능한 필드로, 제작할 때 PE 파일에 제작자가 버전을 기입할 수 있도록 하는 것이다. MajorSubsystem과 MinorSubsystem은 본 PE를 실행하는데 필요한 서브시스템의 최소 버전을 의미한다. Win32VersionValue는 이전엔 예약 필드였지만 VC++ 7.0부터는 이름을 가지게 되었다. 하지만 거의 사용되지 않으며 보통 0으로 설정된다.
SizeOfImage는 PE 파일이 메모리에 로딩되었을 때의 전체 크기를 담고 있으며 이 값은 SectionAlignment 필드 값의 배수가 되어야 한다. SizeOfHeaders는 PE 헤더의 전체 크기를 나타내는 것으로 이 값 역시 FileAlignment의 배수가 되어야 한다.
CheckSum 필드는 이미지의 체크섬 값을 의미한다. PE 파일의 체크섬 값은 IMAGEHELP.DLL의 CheckSymMappedFile API를 통해서 얻을 수 있다. 체크섬 값은 커널 모드 드라이버나 어떤 시스템 DLL의 경우 요구된다. 그 이외의 경우라면 보통 0으로 설정된다. 그리고 Subsystem 필드의 경우 sys 파일과 같이 디바이스 드라이버 같은 경우 1의 값을 가지고 Windows GUI 프로그램의 경우 윈도우 기반 응용프로그램의 경우 2, 마지막으로 CMD와 같은 콘솔 기반 응용프로그램은 3의 값을 갖는다.
DllCharacteristics 필드는 원래 PE가 DLL이라는 전제 하에 어떤 상황에서 DLL 초기화 함수가 호출되어야 하는지를 지시하는 플래그였다. 하지만 지금은 대부분 0으로 설정되어 있는 것을 확인할 수 있다.
SizeOfStackReserve, SizeOfStackCommit, SizeOfHeapReserve, SizeOfHeapCommit 필드에 대하여 알아보자. 프로세스는 가상 주소 공간에 자신만의 스택과 힙을 별도로 가진다. 따라서 프로세스 생성 시 시스템은 언제나 메인 스레드를 위한 디폴트 스택과 프로세스를 위한 디폴트 힙을 해당 프로세스 내에 생성시켜주는데, 이 스택과 힙의 크기와 속성에 관계된 설정을 이 필드들에 지정하게 된다. PE가 메모리에 로드될 때 시스템은 이 필드의 값을 참조하여 해당 프로세스에 디폴트 스택과 힙을 만들어준다.
LoaderFlags 필드는 이전에는 디버깅 지원에 관계된 목적으로 존재하는 것 같지만, 현재는 0으로 설정된다. NumberOfRvaAndSize 필드는 바로 뒤에 나오는 IMAGE_DATA_DIRECTORY 구조체 배열의 원소 개수를 의미하는데, 이 값은 항상 16(0x10)이다.
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY; |
그림 19. IMAGE_DATA_DIRECOTRY 구조체
IMAGE_DATA_DIRECTORY는 구조체의 배열로, 배열의 각 항목마다 정의된 값을 가지게 된다. 각 항목은 위와 같이 VirtualAddress와 Size 필드로 구성되어 있으며 각 16개의 구조는 다음과 같은 의미를 가진다.
ENTRY | 설명 |
IMAGE_DIRECTORY_ENTRY_EXPORT | Export Section의 시작 주소를 가리킨다. |
IMAGE_DIRECTORY_ENTRY_IMPORT | Import Section의 시작 주소를 가리킨다 |
IMAGE_DIRECTORY_ENTRY_RESOURCE | Resource Section의 시작 주소를 가리킨다. |
IMAGE_DIRECTORY_ENTRY_EXCEPTION | 예외 핸들러 테이블을 가리킨다. |
IMAGE_DIRECTORY_ENTRY_SECURITY | WinTrust.h에 정의된 WIN_CERTIFICATE 구조체들의 리스트의 시작 번지를 가리킨다. 이 리스트는 메모리 상에 매핑되지 않기 때문에 VirtualAddress필드는 RVA가 아닌 Offset이다. |
IMAGE_DIRECTORY_ENTRY_BASERELOC | ImageBase를 기준으로 메모리에 매핑되지 않을 경우 코드 상의 포인터 연산과 관련된 주소를 다시 갱신해야하는 "재배치"가 일어나야 하는데, 이를 위한 재배치 섹션을 가리킨다. |
IMAGE_DIRECTORY_ENTRY_DEBUG | 해당 이미지의 디버그 정보를 기술하고 있는 곳을 가리킨다. |
IMAGE_DIRECTORY_ENTRY_ARCHITECTURE | IMAGE_ARCHITECTURE_HEADER 구조체의 배열에 대한 포인터이다. x86 또는IA-64계열에서는 사용되지 않는다. |
IMAGE_DIRECTORY_ENTRY_GLOBALPTR | 글로벌 포인터(GP)로 사용되는 RVA를 나타내며 Size필드는 사용되지 않는다. |
IMAGE_DIRECTORY_ENTRY_TLS | Thread Local Storage 초기화 섹션에 대한 포인터이다. |
IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG | IMAGE_LOAD_CONFIG_DIRECTORY 구조체에 대한 포인터이다. |
IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT | DLL 바인딩과 관련된 정보를 담고 있는 곳을 가리키는 포인터이다. |
IMAGE_DIRECTORY_ENTRY_IAT | 첫 번째 IAT의 시작 번지를 가리키며 Size 필드는 모든 IAT의 전체 크기를 가리킨다. |
IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT | 지연 로딩에 대한 정보를 가리키는 포인터다. |
IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR | .NET 응용 프로그램이나 DLL 용 PE를 위한 것으로 PE 내의 .NET 정보에 대한 최상위 정보의 시작 번지를 가리킨다. |
NULL | 마지막 엔트리는 항상 NULL 값이다. |
그림 20. IMAGE_DATA_DIRECTORY ENTRY
IMAGE_SECTION_HEADER
PE 헤더 바로 다음엔 IMAGE_SECTION_HEADER가 나온다. 섹션 헤더는 각 섹션의 속성이 정의되어 있는 구조체로 각 섹션 헤더 마다 40 Bytes로 구성된다. 각 필드에 대하여 알아보자.
typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER; |
그림 21. IMAGE_SECTION_HEADER 구조체
Name 필드는 섹션의 아스키 이름을 나타내며 만약 섹션의 이름이 8 Bytes를 넘을 경우 8 Bytes 이후의 문자열은 잘린 뒤 이 필드 값을 채운다. 또한 이 값은 섹션의 이름을 참고할 용도뿐이라 해당 이름을 바꾸어도 프로그램의 실행에는 아무런 지장이 없다.
PhysicalAddress필드는 이전엔 OBJ 파일에서 섹션의 물리적인 번지를 지정했지만, 지금은 사용되지 않아 0으로 지정되어 있다. VirtualSize 필드는 메모리에서 섹션이 차지하는 크기를 나타낸다. VirtualAddress는 PE에서 해당 섹션을 매핑시켜야 할 가상 주소 공간 상의 RVA를 가지고 있다. SizeOfRawData는 파일에서 섹션이 차지하는 크기를 나타낸다. 그리고 PointerToRawData는 파일에서 해당 섹션의 위치를 나타낸다.
PointerToRelocations는 본 섹션을 위한 재배치 파일 오프셋으로 OBJ 파일에서만 사용되고 실행파일에서는 0이 된다. PointerToLinenumbers는 본 섹션을 위한 COFF 스타일의 라인 번호를 위한 파일 오프셋이다.
NumberOfRelocations는 PointerToRelocations 필드가 가리키는 구조체 배열의 원소 개수를 나타내며, NumberOfLinenumbers는 PointerToLinenumbers 필드가 가리키는 구조체 배열의 원소 개수를 나타낸다.
마지막으로 Characteristics는 해당 섹션의 속성을 나타내는 플래그의 집합으로 아래와 같은 속성 값이 존재하고 있다.
속성 값 | 설명 |
IMAGE_SCN_CNT_CODE(0x20) | 섹션이 코드를 포함하고 있다. |
IMAGE_SCN_CNT_INITIALIZED_DATA(0x40) | 섹션이 초기화된 데이터를 포함하고 있다. |
IMAGE_SCN_CNT_UNINITIALIZED_DATA(0x80) | 섹션이 초기화되지 않은 데이터(ex.bss)를 가지고 있다. |
IMAGE_SCN_MEM_DISCARDABLE(0x2000000) | 이 섹션은 실행 이미지가 메모리에 완전히 매핑되고 난 뒤 버려질 수 있다. |
IMAGE_SCN_MEM_NOT_CACHED(0x4000000) | 해당 섹션은 페이지되지 않거나 캐쉬되지 않는다. 페이지 되지 않는다는 것은 페이지 파일로 스왑되지 않는다는 것을 의미하며 이는 항상 RAM에 존재하는 섹션임을 의미한다. |
IMAGE_SCN_MEM_NOT_PAGED(0x8000000) |
IMAGE_SCN_MEM_SHARED(0x10000000) | 이 섹션은 공유 가능한 섹션임을 나타낸다. |
IMAGE_SCN_MEM_EXECUTE(0x20000000) | 이 섹션은 실행 가능하 섹션임을 나타낸다. |
IMAGE_SCN_MEM_READ(0x40000000) | 이 섹션은 읽기 가능한 섹션이다. |
IMAGE_SCN_MEM_WRITE(0x80000000) | 이 섹션은 쓰기 가능한 섹션이다. |
IMAGE_SCN_LNK_INFO(0x0x200) | 해당 섹션이 링커에 의해 사용될 주석이나 다른 어떤 종류의 정보를 가진다. |
IMAGE_SCN_LNK_REMOVE(0x800) | 링크 시에 최종 실행 파일의 일부가 되지 말아야 할 섹션의 내용들을 지시한다. |
IMAGE_SCN_LINK_COMDAT | 해당 섹션의 내용들은 공용 데이터이다. |
IMAGE_SCN_ALIGN_XBYTES | _XBYTES의 값으로 _1BYTES부터 _8192Bytes까지의 정렬 단위를 나타낸다. 특별히 지정되지 않으면 디폴트로 16바이트에 해당하는 IMAGE_SCN_ALIGN_16BYTES가 된다. |
그림 22. IMAGE_SECTION_HEADER 속성 값
.code 섹션의 경우 주로 CNT_CODE, MEM_EXECUTE, 그리고 MEM_READ 속성 값을 가지며 .data 섹션과 .idata 섹션의 경우 CNT_INITALIZED_DATA, MEM_READ, 그리고 MEM_WRITE의 속성 값을 가진다.
Section
각 PE 파일마다 가지는 섹션은 다를 수 있지만, 대부분 섹션은 유사한 기능을 한다. 그러므로 이러한 각 섹션에 대하여 알아보자.
Code Section
코드 섹션 또는 텍스트 섹션은 컴파일러나 어셈블러가 최종적으로 생성하는 일반 목적 코드가 존재하는 섹션으로 실행 명령어들이 이곳에 존재하고 있다. 우선 예제 파일을 통해 실제 코드 섹션의 내용을 확인해보자. 아래의 바이너리와 같이 우리가 읽을 수 없는 코드로 이루어져 있기 때문에 우리는 기계어를 해석하기 위하여 디스어셈블러와 같은 도구를 사용하여야 한다.
00000600 : 6A 00 68 00 20 40 00 68 12 20 40 00 6A 00 E8 4E j.h. @.h. @.j..N
00000610 : 00 00 00 68 94 20 40 00 E8 38 00 00 00 46 48 EB ...h. @..8...FH.
00000620 : 00 46 46 48 3B C6 74 15 6A 00 68 35 20 40 00 68 .FFH;.t.j.h5 @.h
00000630 : 3B 20 40 00 6A 00 E8 26 00 00 00 EB 13 6A 00 68 ; @.j..&.....j.h
…(skip) |
그림 23. 예제.exe의 .text 섹션
디스어셈블러를 통해 해당 섹션의 내용을 확인하면 아래와 같은 명령어가 위치해있는 것을 알 수 있다. 이러한 명령어들이 하나 하나 실행되면서 프로그램의 정의된 대로 동작하게 된다. 실행의 흐름을 위하여 EIP 레지스터에는 실행할 명령어의 위치가 담겨 있다.
00401000 |. 6A 00 PUSH 0 ; /Style = MB_OK|MB_APPLMODAL
00401002 |. 68 00204000 PUSH test1.00402000 ; |Title = "abex' 1st crackme"
00401007 |. 68 12204000 PUSH test1.00402012 ; |Text = "Make me think your HD is a CD-Rom."
0040100C |. 6A 00 PUSH 0 ; |hOwner = NULL
0040100E |. E8 4E000000 CALL <JMP.&USER32.MessageBoxA> ; \MessageBoxA
...(skip) |
그림 24. 예제.exe의 .text 섹션 – 어셈블리 코드
그렇다면 왜 파일에서의 위치(Offset)은 0x600인데 메모리에서의 위치(RVA)는 401000일까? 아무 이유 없이 이렇게 메모리에 올라오는 것이 아니라, 이전에 언급한 바와 같이 ImageBase나 해당 섹션의 RVA, PointerToRawData 등에 의해 메모리에 올라오면서 정의된 대로 위치하게 되는 것이다. 해당 프로그램의 필드 값 몇가지를 확인해보자.
필드 이름 | 필드 값 |
ImageBase | 0x400000 |
RVA | 0x1000 |
PointerToRawData | 0x600 |
그림 25. 예제.exe의 몇 가지 필드 값
우선 코드 섹션의 PointerToRawData는 0x600으로 파일에서 해당 섹션의 위치가 0x600임을 알려준다. 그렇기에 해당 위치를 확인해보면 실행할 코드가 존재하고 있는 것을 확인할 수 있다. 메모리에서 해당 섹션의 위치는 RVA인 0x1000으로 이에 ImageBase 값을 더하면 위 그림에서의 주소인 0x401000임을 알 수가 있다. 이처럼 RVA와 RAW(Offset)의 주소의 관계는 직접 코드를 파일에서 수정하고자 할 때와 같은 경우에, 이를 변환할 줄 알아야 한다.
코드 섹션에 실행을 위한 명령어들이 있다고 하여 .text 섹션의 첫 부분이 프로그램의 실행을 위한 첫 명령어가 아니다. 흔히 디버거를 통해 프로그램의 시작 부분으로 이동되는 주소는 Entry Point로 IMAGE_OPTIONAL_HEADER의 AddressOfEntryPoint에 ImageBase를 더한 위치가 프로그램의 시작 주소가 된다.
Data Section
데이터 섹션은 그 종류가 여러 가지이다. 일반적으로 .data라는 이름을 가진 섹션이 존재하며 이 안에 .idata나 .edata, 또는 .rdata 섹션이 존재하기도 한다. 이에 대해서는 뒤에서 상세히 다룰 것이다. 데이터 섹션은 그 속성이 읽기/쓰기 가능한 섹션으로 전역 변수나 정적 변수를 정의하게 되면 이러한 변수들이 이 섹션에 위치하게 된다.
아래는 실제 예제 프로그램의 데이터 섹션이다. 해당 데이터 섹션에는 ASCII 형태의 문자열들이 존재하고 있는 것을 확인할 수 있다.
00000800 : 61 62 65 78 27 20 31 73 74 20 63 72 61 63 6B 6D abex' 1st crackm
00000810 : 65 00 4D 61 6B 65 20 6D 65 20 74 68 69 6E 6B 20 e.Make me think
00000820 : 79 6F 75 72 20 48 44 20 69 73 20 61 20 43 44 2D your HD is a CD-
00000830 : 52 6F 6D 2E 00 45 72 72 6F 72 00 4E 61 68 2E 2E Rom..Error.Nah..
00000840 : 2E 20 54 68 69 73 20 69 73 20 6E 6F 74 20 61 20 . This is not a
00000850 : 43 44 2D 52 4F 4D 20 44 72 69 76 65 21 00 59 45 CD-ROM Drive!.YE
00000860 : 41 48 21 00 4F 6B 2C 20 49 20 72 65 61 6C 6C 79 AH!.Ok, I really
00000870 : 20 74 68 69 6E 6B 20 74 68 61 74 20 79 6F 75 72 think that your
00000880 : 20 48 44 20 69 73 20 61 20 43 44 2D 52 4F 4D 21 HD is a CD-ROM!
00000890 : 20 3A 70 00 63 3A 5C 00 00 00 00 00 00 00 00 00 :p.c:\......... |
그림 26. 예제.exe의 .data Section
데이터 섹션과 유사 .rdata 섹션은 읽기 전용 데이터 섹션으로 해당 섹션 헤더를 확인해보면 MEM_WRITE 속성이 존재하지 않는 것을 확인할 수 있다. 따라서 이 섹션에 무엇인가 기록하고자 하면 시스템은 예외를 나타내며 프로그램이 종료될 것이다. 또한 .rdata 섹션은 이러한 용도뿐만아니라 다른 섹션들이 병합되는 곳이기도 하다. 이후에 나올 .edata나 .idata 섹션이 .rdata섹션에 병합되는 경우도 종종 있다는 것을 잊지 말자.
Export Section
Export 섹션은 주로 DLL에서 나타나는 섹션으로 자신이 가진 함수의 기능을 외부 프로그램이 사용할 수 있도록 제공하는 것이 목적이다. 만약 A.exe와 B.exe라는 프로그램이 존재할 때 두 프로그램 모두 TEST_Function()이라는 함수를 정의하여 사용하고 있다고 가정하자. 두 프로그램에 있어 TEST_Function을 각각 써넣어주는 것보단 용량이나 이후 관리를 위하여 TEST_Function()을 가진 DLL을 하나 만든 다음 이를 Import하여 사용할 수 있다. 반대로 해당 DLL은 Export를 제공하는 것이다.
먼저 Export Section의 IMAGE_EXPORT_DIRECTORY 구조체에 대하여 알아보자. 해당 구조체는 Export Section에서 가장 중요한 정보들을 담고 있는 구조체이며, IAT와는 다르게 PE 파일 당 하나만 존재한다. 해당 필드의 목록은 아래의 그림과 같다.
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name;
DWORD Base;
DWORD NumberOfFunctions;
DWORD NumberOfNames;
DWORD AddressOfFunctions;
DWORD AddressOfNames;
DWORD AddressOfNameOrdinals;
} IMAGE_EXPORT_DIRECTORY,*PIMAGE_EXPORT_DIRECTORY; |
그림 27. IMAGE_EXPORT_DIRECTORY 구조체
첫 번째부터 필드는 사용되지 않으며 두 번째 필드는 해당 파일이 생성된 시간을 나타낸다. 그 다음 버전과 관련된 필드 역시 사용되지 않는다. 다섯 번째 Name필드는 해당 DLL의 이름을 나타내는 ASCII 코드 문자열의 위치를 지시하는 RVA이다. 파일에서 해당 DLL의 이름은 RVA를 RAW로 변환해주면 해당 Offset에서 이름을 확인할 수 있다. Base 필드는 Export된 함수들에 대한 서수의 시작 번호이다.
NumberOfFunctions는 뒤에 나오는 AddressOfFunctions 필드가 가리키는 RVA 배열의 원소 개수를 나타낸다. AddressOfFunctions는 export된 함수들의 함수 포인터를 가진 배열을 가리킨 RVA 값으로 이 함수 주소들은 본 모듈 내에서 각각 export된 함수에 대한 엔트리 포인터이다.
NumberOfNames는 AddressOfNames 필드가 가리키는 RVA 배열의 원소 개수와 AddressOfNameOrdinals 필드가 가리키는 서수 배열의 원소 개수를 동시에 나타낸다. AddressOfNames 필드는 export된 함수의 심벌을 나타내는 문자열 포인터 배열을 가리키는RVA 값이고, AddressOfNameOrdinals는 export된 모든 함수들의 서수를 담고 있는 배열에 대한 포인터이다.
여기서 NumberOfNames와 NumberOfFunctions은 다를 수 있는데 보통 NumberOfFunctions 필드가 더 크거나 같다. 하지만 실제 export된 함수의 정확한 개수는 NumberOfNames 필드의 값이다. 이렇게 IMAGE_EXPORT_DIRECTORY에 대하여 알아보았다. 아래는 실제 DLL 파일의 .edata 섹션을 분석한 내용이다.
구조체 | 필드 | 값 |
IMAGE_EXPORT_DIRECTORY | Characteristics | 0000 |
TimeDateStamp | 2009/07/13 23:38:00 UTC |
Major Version | 0 |
Minor Version | 0 |
Name RVA | 10DA4(adsnsext.dll) |
Ordinal Base | 1 |
Number Of Functions | 2 |
Number Of Names | 2 |
Address Of Functions | 10D90 |
Address Of Names | 10D98 |
Address Of Name Ordinals | 10DA0 |
구조체 | 데이터 | 값 |
Export Address Table | 2D6C | DllCanUnloadNow |
2D51 | DllGetClassObject |
Export Name Pointer Table | 10DB1 | DllCanUnloadNow |
10DC1 | DllGetClassObject |
Export Ordinal Table | 0001 | DllCanUnloadNow |
0002 | DllGetClassObject |
그림 28. 예제.dll의 .edata 섹션
IMAGE_EXPORT_DIRECTORY 구조체 외에 3개의 Export Table이 존재하는 것을 확인할 수 있다. 하나는 Export 함수 포인터 테이블이며 다른 하나는 Export 함수 이름 포인터 테이블, 마지막으로 Export 함수 서수 테이블임을 알 수가 있다.
Import Section
DLL의 입장에서는 함수를 Export 해주었다면 반대로 그 함수를 사용하기 위해선 다른 실행파일에서 이를 Import 해주어야 한다. 이렇게 사용하고자 import 하는 함수들과 그 DLL에 대한 정보를 가지고 있는 것이 바로 임포트 섹션이다. 아래 IMAGE_IMPORT_DESCRIPTOR 구조체를 확인해보자.
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics;
DWORD OriginalFirstThunk; // INT Address (RVA)
} DUMMYUNIONNAME;
DWORD TimeDateStamp;
DWORD ForwarderChain;
DWORD Name;
DWORD FirstThunk; // IAT Address (RVA)
} IMAGE_IMPORT_DESCRIPTOR,*PIMAGE_IMPORT_DESCRIPTOR; |
그림 29. IMAGE_IMPORT_DESCRIPTOR 구조체
우선 첫 번째 필드인 Characteristics 필드는 더 이상 사용하지 않고 OriginalFirstThunk라는 이름의 필드로 사용한다. OriginalFirstThunk 필드는 INT(Import Name Table)의 RVA 주소 값을 가지고 있다. 그 다음 TimeDataStamp는 시간과 날짜를 나타내며, 바인딩되지 않을 경우 항상 0이다. ForwarderChain 필드는 바인딩 여부와 관계되는 필드로 바인딩 되지 않은 이미지의 경우 0 이며 바인딩된 경우 이 값은 0이 아니다. Name 필드는 import된 DLL의 이름이 존재하는 RVA 값을 가진다. 마지막으로 FirstThunk 필드는 IAT(Import Address Table)의 RVA 주소 값을 가지고 있다.
이러한 구조는 로드하는 DLL의 수만큼 존재하며 맨 마지막에는 NULL로 채워진 해당 구조체가 존재하므로 배열의 끝을 알려준다. IMAGE_IMPORT_DESCRIPTOR의 필드 항목을 통해 알 수 있는 INT와 IAT의 값을 확인해보자.
배열 이름 | 오프셋 | 데이터 | 값 |
Import Name Table | 0x00000A3C | 0x0000307C | GetDriveTypeA |
0x00000A40 | 0x0000308C | ExitProcess |
0x00000A44 | 0x00000000 | KERNEL32.DLL |
0x00000A48 | 0x0000309A | MessageBoxA |
0x00000A4C | 0x00000000 | USER32.DLL |
Import Address Table | 0x00000A50 | 0x0000307C | GetDriveTypeA |
0x00000A54 | 0x0000308C | ExitProcess |
0x00000A58 | 0x00000000 | KERNEL32.DLL |
0x00000A5C | 0x0000309A | MessageBoxA |
0x00000A60 | 0x00000000 | USER32.DLL |
그림 30. INT와 IAT
여기서 INT와 IAT가 동일한 값을 가리킨다는 것을 알 수 있다. 하지만 메모리에 올라오면서 PE 로더가 IAT엔 실제 함수의 명령어 위치를 채워주게 되며, INT에는 파일에서와 마찬가지로 임포트하는 함수의 이름을 가리키고 있다. 그렇다면 메모리에서 IAT 기록되어 있는 함수의 주소는 어떻게 얻어오는 것일까? 크게 네 단계로 나눌 수가 있다. 아래의 그림을 보자.

그림 31. IAT에 함수 주소 기록 과정
우선 로더는 A.EXE 파일이 필요로 하는 DLL을 로드하고자 한다. 이를 위해 Import 섹션의 존재하고 있는 IMAGE_IMPORT_DESCRIPTOR(IID)를 통해 어떠한 DLL을 필요로 하는지 이름을 얻는다. 그리고 해당 DLL들을 LoadLibrary API를 통해 메모리에 올리고자 한다. 해당 DLL을 찾은 프로세스는 DLL을 매핑하기 위한 공간을 확보한 다음 ImageBase에 지정된 주소로 매핑을 시도하며, 만약 해당 주소에 매핑하지 못한 경우 재배치를 하여 다른 주소에 매핑을 한다.
매핑이 되었다면 로더는 IID의 OriginalFirstThunk 필드를 통해 INT에 존재하고 있는 함수에 대한 정보를 얻어온다. 그 다음으로 로더는 해당 함수들의 함수 포인터 즉, 함수의 시작 주소를 얻고자 획득하고자 한다.
로더는 dll의 Export 섹션에서 IMAGE_EXPORT_DIRECTORY 구조체를 참고하여 AddessOfName 멤버를 통해 해당 함수의 이름을 비교하여 원하는 함수의 이름을 찾는다. 이때 몇 번째 인덱스에 존재하는지 확인을 한 다음 AddressOfNameOrdinals 필드를 참조한다. Ordinal 배열에서 해당 인덱스 번호에 맞는 값을 찾은 뒤, AddressOfFunctions 멤버를 이용해 EAT에서 해당 인덱스 번호에 맞는 함수의 시작 주소(RVA)를 얻는다.
마지막으로 해당 함수의 포인터를 획득한 다음 로더는 중요한 과정을 수행하게 되는데, 바로 위 과정을 통해 얻은 함수의 포인터(함수의 시작 주소)를 저장하는 것이다. IID의 FirstThunk 필드 값을 통해 IAT의 주소를 얻을 수가 있고, 첫 번째 과정에서 읽은 것과 같은 함수에 세 번째 과정에서 얻은 함수의 시작 주소를 기록하게 된다.
이러한 과정을 통해 파일에서 IAT는 INT와 같은 곳을 가리키지만, 메모리에서는 INT와는 전혀 다른 실제 함수의 시작 위치를 가리키고 있게 된다. 다시 말해, IAT는 PE 파일 이미지로 존재할 때와 실제로 프로세스 주소 공간 내로 매핑되었을 때의 내용이 달라진다. DLL 바인딩을 할 경우 DLL을 로딩하기 전에, IAT에 실제 함수의 주소를 고정시켜버리게 되어 프로그램이 실행될 때마다 이러한 과정을 거치지 않게 된다.
Relocation Section
앞서 논의한 바와 같이 로더는 실행 파일을 로드할 때 지정된 ImageBase에 실행 파일 이미지를 로드하고자 한다. 하지만 해당 주소에 이미 다른 실행 파일 이미지가 로드되어 있는 경우 중첩되어 그 주소를 사용할 수는 없다. 이런 경우 로더는 매핑 가능한 다른 주소를 찾아 해당 주소에 로드해야한다. 대부분의 DLL은 0x10000000 영역이 기본 ImageBase로 처음에 로드되는 DLL의 경우 상관 없지만 두 번째부터는 다른 주소를 사용해야만 한다.
로딩 주소가 바뀌게 되면 절대 주소를 사용한 것은 반드시 바뀐 주소에 해당하는 값으로 고쳐 주어야 한다. 그렇지 않으면 0x10000000에 로딩된 다른 DLL의 메모리 영역을 참조하게 된다. PE에서는 이렇게 고쳐 주어야 하는 곳을 재배치 섹션에 모아서 저장해 두고 있다. 재배치 섹션의 구조를 한번 살펴보자.
typedef struct _IMAGE_BASE_RELOCATION
{
DWORD VirtualAddress;
DWORD SizeOfBlock;
/* WORD TypeOffset[1]; */ // 이후에 해당 배열이 뒤에 따라옴을 알려줌
} IMAGE_BASE_RELOCATION,*PIMAGE_BASE_RELOCATION; |
그림 32. IMAGE_BASE_RELOCATION 구조체
기준 재배치 섹션은 단순한 구조를 가지고 있다. VirtualAddress 필드는 기준 재배치가 시작되어야 할 메모리 상의 번지에 대한 RVA이다. 실제 갱신할 위치의 표현은 "기준 RVA+재배치 Offset"으로 구성되고 이때 기준 RVA에 해당하는 것이 이 필드의 값이다. 재배치 섹션 내의 재배치 블록은 4K 단위의 구조체를 포함하는 블록이 존재하기에 나뉘어지는데, 이때 SizeOfBlock 필드의 값은 자신을 포함하고 있는 구조체의 크기를 말한다.
이 뒤에는 재배치가 적용되어야 할 대상에 해당하는 가상 주소에 대한 정보를 담은 WORD 타입의 배열이 온다. 해당 배열의 각 엔트리는 두 필드로 구성되는데 하나는 재배치 타입이며, 다른 하나는 재배치 오프셋이다.
Bit | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
WORD | 재배치 타입 | 재배치 오프셋 |
그림 33. TypeOffset 엔트리 구조
재배치 타입의 경우 거의 큰 의미가 없는 값으로 Win32 PE의 경우 3, Win64의 경우 10이 된다. 가끔 재배치 그룹의 마지막 엔트리에 이 필드의 값이 0인 경우가 있는데 이는 해당 구조체가 4 바이트 단위로 정렬되기 때문에 이것을 맞추어 주기 위한 패딩으로 사용될 뿐이다.
다음으로 재배치 오프셋은 재배치할 대상의 번지 값에 대한 오프셋이다. 오프셋의 기준은 위에서 언급하였던 IMAGE_BASE_RELOCATION 구조체의 VirtualAddress 필드의 값이 된다. 따라서 실제로 갱신되어야 할 위치의 RVA는 VirtualAddress 필드 값에 재배치 오프셋 값을 더한 결과가 된다.
재배치 오프셋이 12 Bit 밖에 되지 않아 기준이 되는 VirtualAddress로부터 4095만큼까지만 접근이 가능하다. 그렇다면 그 이상으로 떨어진 지점은 어떻게 표현할까? 새로 VirtualAddress를 지정해주면 된다. 즉 하나 이상의 VirtualAddress 필드가 존재할 수 있으며 이에 따라 각 배열이 뒤에 붙게 된다.
재배치는 다음의 과정으로 이루어진다. 만약 ImageBase의 값과 실제 로드될 주소가 다른 경우 그 값의 차이인 델타 값을 구한다. 예로 원래는 0x10000000에 로드될 a.dll이 0x15000000에 로드되었다면 델타 값은 0x05000000이 된다. 그 다음 아래와 같은 재배치 섹션을 확인해보자.
pFile | Data | Description |
0x000C1A00 | 0x00010000 | VirtualAddress |
0x000C1A04 | 0x0000001C | SizeOfBlock |
0x000C1A08 | 0x3E15 | TypeOffset[0] |
0x000C1A0A | 0x3E41 | TypeOffset[1] |
그림 34. a.dll의 재배치 섹션
VirtualAddress 필드 값이 0x10000인 것을 확인할 수 있다. 해당 섹션은 .text 섹션으로 TypeOffset를 따라가보자. 해당 RVA 0x10000의 RAW는 0x600으로 재배치 오프셋인 0xE15과 0xE41를 각각 더하면 TypeOffset[0]이 나타내는 파일에서의 주소는 0x1215와 0x1241이 된다. 해당 값을 확인해보자.
00001210 : 1C 53 56 8B 35 18 03 E4 6D 57 8B 78 10 85 F6 0F .SV.5...}W.x....
00001220 : 85 0A 01 00 00 E8 B0 09 00 00 8B 40 2C 64 8B 0D ...........@,d..
00001230 : 18 00 00 00 6A 44 5B 53 50 8B 41 30 FF 70 18 FF ....jD[SP.A0.p..
00001240 : 15 E4 05 D7 6D 8B F0 33 C0 3B F0 0F 84 5D 01 00 ....}..3.;...].. |
그림 35. 재배치 해야할 주소 확인
이 위치에 있는 것이 무엇을 뜻하는지 어셈블리어로 확인해보자. 첫 번째 TypeOffset[0]은 MOV 명령어의 오퍼랜드로 사용되고 두 번째 TypeOffset[1]은 CALL 명령어에 사용되는 것을 확인할 수 있다.
10001083 8B35 1803E47D
MOV ESI,DWORD PTR DS:[6DE40318]
…(skip)
100010AF FF15 E405D77D
CALL DWORD PTR DS:[6DD705E4] |
그림 36. 재배치 할 주소의 명령어
재배치 해야할 값을 찾았으니 이제 이 값에 위에서 구한 델타 값 0x05000000을 각각 더해주게 된다. 따라서 0x1215에 있는 값은 0x15000000에 매핑된 이후 [0x6DE40318+0x05000000]이 되며, 0x1241에 있는 값은 매핑된 이후 [0x6DD705E4+0x05000000]이 된다. 이와 같이 재배치 섹션은 어떠한 값을 바꾸어야 하는지 알려주는 역할을 한다.
하지만 기준 재배치를 수행해야 할 상황이 되었을 때 발생할 수 있는 문제점 또한 존재한다. 크게 두 가지 문제점이 있는데 첫째로, 로더는 재배치 섹션을 스캔하면서 재배치 섹션 내에 존재하는 각 오프셋이 가리키는 위치의 해당 모듈의 코드를 모두 수정해야한다. 이것은 응용프로그램의 초기화 시간을 더 늘어나게 만든다.
둘째로, 로더가 재배치 섹션의 엔트리가 지시하는 해당 번지 값을 수정할 때 발생하는 문제가 있다. 갱신되어야 할 해당 주소 공간의 번지 값은 .text 섹션에 존재하는데, 코드 섹션의 경우 Write 속성이 없기 때문에 결국 번지 값을 수정하기 위해 섹션의 속성을 변경해야만 한다.
API Hooking
위 과정에서 본 것과 같이 IAT는 읽을 수 있을 뿐만 아니라 쓰기 속성을 가지고 있다. 따라서 이러한 속성을 이용해 기존의 API에 대한 호출을 자신이 정의한 API로 향하도록 변경할 수 있다. 이를 API 후킹이라 한다. 이번 장에서는 DLL 인젝션을 진행하는 방법과 IAT 후킹에 대하여 알아보자.
DLL Injection
몇 가지 인젝션 방법 중 세 가지 방법에 대하여 알아보자. 우선 DLL 인젝셕은 다른 프로세스에게 강제로 DLL을 로딩시키도록 하는 것으로, 원하는 기능을 수행하는 DLL을 다른 프로세스에 매핑시켜 원하는 동작을 수행하도록 한다. 여러 방법 중 우선 CreateRemoteThread API를 이용하는 방법에 대하여 알아보자.
흔히 DLL을 자신의 프로세스에 로드하기 위해서는 LoadLibrary API를 사용한다. 하지만 다른 프로세스에게 LoadLibrary API를 사용하여 DLL을 로드 시킬 수가 없으므로 CreateRemoteThread API를 통해 다른 프로세스에게 스레드를 실행시키도록 하여 DLL을 로드시킬 수 있다.
HANDLE WINAPI CreateRemoteThread(
_In_ HANDLE
hProcess, // 프로세스 핸들
_In_ LPSECURITY_ATTRIBUTES
lpThreadAttributes,
_In_ SIZE_T
dwStackSize,
_In_ LPTHREAD_START_ROUTINE
lpStartAddress, // 스레드 함수 주소
_In_ LPVOID
lpParameter,
// 스레드 파라미터 주소
_In_ DWORD
dwCreationFlags,
_Out_ LPDWORD lpThreadId
); |
그림 37. CreateRemoteThread API
위에는 CreateRemoteThread API의 인자로 어떠한 것이 있는지 나타내는 것으로 중요한 항목은 바로 네 번째 인자인 lpStartAddress이다. 해당 파라미터는 스레드가 수행할 함수의 주소를 넘겨주는 것으로 다른 프로세스에서 수행할 함수의 주소를 말한다. 바로 여기에 LoadLibrary API의 주소를 주고, 다섯 번째 인자에 로드시키고자 하는 DLL의 이름을 넘겨주면 된다.
다음으로 레지스트리를 통해 쉽게 DLL Injection하는 방법에 대하여 알아보자. 바로 AppInit_DLLs라는 레지스트리 키로 여기에 인젝션하고자 하는 DLL의 경로를 기입해준 뒤 재부팅을 시행하면, 재부팅하면서 실행되는 모든 프로세스에 해당 DLL을 인젝션 시켜준다. 위 CreateRemoteThread가 하나의 프로세스를 지정해주는 것과는 다르게 모든 프로세스에 시행된다는 점이 차이난다고 할 수 있다. 해당 경로는 다음 과 같다.
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Windows\AppInit_DLLs |
그림 38. AppInit_DLLs Registry Key
마지막으로 알아본 DLL 인젝션 방법은 윈도우 운영체제가 제공하는 API를 사용하는 방법이다. 윈도우 운영체제는 사용자에게 GUI를 제공해주고, 사용자는 제공받은 GUI를 이용하여 원하는 동작을 수행할 수 있다. 동작을 수행하는데 있어 마우스나 키보드와 관련된 동작을 수행하게 되는데 이러한 동작은 윈도우 운영체제가 Event Driven 방식으로 처리한다. 다시 말해 이러한 동작을 이벤트로 발생시켜 운영체제가 그 이벤트에 맞는 메시지를 해당 응용 프로그램에게 전달하여 처리하는 방식이다.
아래 그림을 보면 메시지 후킹이 어떤 지점에서 이루어지는지 볼 수 있다. 사용자가 어떠한 행위를 했을 때 이벤트가 발생되고, 이벤트 발생으로 인해 OS에서 응용 프로그램으로 보낼 메시지들이 OS Message Queue에 추가된다. 운영체제는 해당 이벤트가 어떤 응용 프로그램에서 발생했는지 파악한 다음, OS 큐에서 메시지를 꺼내 해당 응용 프로그램의 메시지 큐에 전달한다. 해당 응용 프로그램은 자신의 응용 프로그램 메시지 큐에 해당 메시지가 추가된 것을 확인하고 해당 이벤트 핸들러를 호출한다. 이러한 방식으로 윈도우는 메시지를 전달한다.

그림 39. 메시지 전달 방식
윈도우 운영체제어서는 이러한 메시지를 후킹하기 위한 API인 SetWindowsHookEx()를 기본적으로 제공한다. 이 API는 훅 체인에 응용 프로그램이 정의한 후크 프로시저를 설치하며 이를 통해 사용자는 특정 유형의 이벤트를 모니터링 할 수 있다.
HHOOK WINAPI SetWindowsHookEx(
_In_ int idHook // 훅 종류
_In_ HOOKPROC lpfn, // 지정한 이벤트 발생시 처리하는 프로시저 주소
_In_ HINSTANCE hMod, // lpfn 이 있는 DLL 의 핸들
_In_ DWORD dwThreadId
); |
그림 40. SetWindowsHookEx API
만약 해당 API를 구현하는 HookKey.dll이 존재하며 이를 실행하기 위한 HookMain.exe를 제작하였다고 가정하자. HookMain.exe를 실행하면 HookKey.dll이 해당 프로세스의 메모리에 로드되며 SetWindowsHookEx()가 호출된다. 이렇게 메시지 후킹이 걸린 상테에서, 다른 프로세스가 해당 이벤트를 발생시킨다면 HookKey.dll은 그 프로세스에서도 로딩된다.

그림 41. SetWindowsHookEx를 이용한 후킹
이러한 방법들을 통해 원하는 DLL을 프로세스에 인젝션 할 수 있다.
IAT Hooking
IAT는 위에서 자세히 설명한 바와 같이 Import Address Table로, 메모리에 매핑되면서 PE 로더가 IAT에 실제 함수의 주소를 기록해준다. 다시 말해 파일에서의 IAT는 실제 함수의 주소를 가리키고 있는 것이 아니며 일반적으로 INT와 같은 곳을 가리키고 있다. 하지만 메모리에 올라온 뒤에는 해당 프로그램이 사용하고자 하는 함수의 주소가 기록되어 있다.
IAT 후킹은 바로 이 IAT에 기록되어 있는 주소를 바꿔 원하는 함수의 주소로 가도록 하는 것이다. 이를 통해 다양한 파라미터나 리턴 값을 조작하는 등의 작업을 수행할 수 있다. 그렇다면 일반적으로 API가 호출되는 상황에 대하여 먼저 알아보자.
0040104A . 68 E8030000 PUSH 3E8 ; /Timeout = 1000. ms
0040104F . FF15 68B14300 CALL DWORD PTR DS:[43B168] ; Sleep() API
0043B168 > FF 10 34 76 0A 19 34 76 69 51 34 76 2F 44 34 76 4v.4viQ4v/D4v
763410FF > 8BFF MOV EDI,EDI
76341101 55 PUSH EBP
76341102 8BEC MOV EBP,ESP
…(skip) |
그림 42. 일반적인 API 호출 과정
위 예에서 Sleep API를 호출하고자 할 때 바로 CALL 명령어를 통해 763410FF(Sleep함수)를 호출하는 것이 아니라 DS:[43B168]을 참조해 해당 주소에 있는 763410FF라는 주소를 얻어 이를 호출한다. 그렇다면 왜 바로 CALL 763410FF라 하지 않을까? 이는 DLL의 특성 상 운영체제 버전이나 언어, 서비스 팩에 따라 DLL의 버전이 다르며 해당 함수의 위치가 달라지기 때문에 IAT에 매핑된 주소를 참조하여 함수를 호출하도록 하는 것이다. 바로 43B168가 IAT의 한 부분으로 Sleep 함수의 실제 주소가 메모리에 올라오면서 기록된 것이다.
따라서 IAT를 후킹한다는 것, 좀 더 구체적으로 IAT에서 Sleep()을 후킹하는 것은 바로 해당 API의 실제 주소를 가지고 있는 IAT의 주소(43B168)에 위치한 주소 값을 바꾸는 것이다. 후킹된 모습은 다음과 같다.
0040104A . 68 E8030000 PUSH 3E8 ; /Timeout = 1000. ms
0040104F . FF15 68B14300
CALL DWORD PTR DS:[43B168] ; Sleep() API
0043B168 > 20 10 40 00 0A 19 34 76 69 51 34 76 2F 44 34 76 4v.4viQ4v/D4v
00401020 814424 04 001 ADD DWORD PTR SS:[ESP+4],1000 ; 인자 값 변조
00401028 - E9 D200F475 JMP 763410FF ; Kernel32.Sleep()
763410FF > 8BFF MOV EDI,EDI
76341101 55 PUSH EBP
76341102 8BEC MOV EBP,ESP
…(skip) |
그림 43. 후킹된 API 호출 과정
이전과 똑같이 Sleep()을 호출하기 위해 IAT를 참조하게 된다. 하지만 해당 IAT는 후킹되어 기존의 Sleep() 함수의 주소가 아닌, 후킹 함수의 주소(0x401020)를 가리키고 있다. 결국 프로세스는 Sleep()을 호출했지만 후킹된 주소로 넘어가게 되며, 후킹된 주소에서 파라미터를 변조한 후 원래의 Sleep() 함수로 진입하게 된다.
이와 같은 IAT 후킹은 간단하게 이루어지면서도 해당 프로세스에서 후킹한 함수를 호출할 때마다 후킹 함수를 지나가게 되므로 강력하다고 할 수 있다.