포렌식을 공부하면서 점차 데이터 복구나 수집한 증거를 분석하는 방법에 대하여 점차 관심이 많아지기 시작하였다. 이를 위해선 공통적으로 파일 시스템에 대한 이해가 필요하다고 생각하였고, 그렇기에 현재 사용하고 있는 NTFS에 대하여 먼저 학습해보자 생각하였다.
파일 시스템이나 NTFS에 대하여 이론적으로 더 잘 정리된 많은 문서들이 있으므로, 나는 Python을 통해 접근을 하기 위함을 목적으로 학습을 진행하였다. 이렇게 접근을 한 다음 최종적으로는 $MFT 수집 도구를 만드는 것이 목적이다. 학습을 위한 준비사항은 아래와 같다.
표 1. 사용한 도구
학습은 윈도우 10을 통해 진행하였으며 전체적으로 학습을 하면서 Windows7이나 XP와의 별 차이를 느끼지 못하였다. Prefetch나 Web Artifact에 있어선 좀 상이한 부분이 있지만, 이번 문서에서 다루는 내용에 한해서는 큰 차이가 없었다.

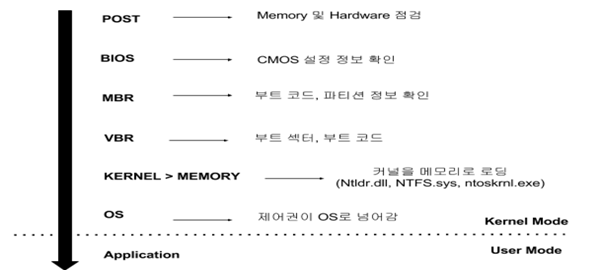
그림 1. 부팅 과정
컴퓨터의 전원을 누른 순간부터 사용자 모드로의 부팅 과정은 위의 그림과 같다. 여기서 BIOS는 ROM에 적재가 되어 있으므로 우리는 MBR부터의 과정을 구체적으로 확인할 수가 있다. 이를 토대로 학습을 진행해보자.
2. 디스크 접근
2.1 HxD 디스크 열기
전체적인 진행을 하기 전에 직접 자신의 디스크를 확인해보자. HxD를 관리자 권한으로 실행을 한 다음, 아래의 버튼과 같이 디스크 열기를 누르면 대개 '논리 디스크'와 '물리 디스크'라 나뉘어 있는 것을 확인할 수가 있다.

그림 2. HxD 디스크 열기
이 중 어떠한 것을 열어야 할 지 모른다면 직접 둘 다 열어서 확인해보자. 어떠한 차이가 있는지는 아래의 그림과 같다. '물리 디스크'를 먼저 확인해보면 알 수 있는 것이 아무것도 없다. 반면에 '논리 디스크'로 연다면 시작과 함께 NTFS라는 문자열이 있다.


그림 3. HxD 디스크 확인
이는 기본적인 디스크를 어떻게 구분하느냐에 따른 것이다. 물리 디스크는 하나의 장치 그 자체를 말하는 것이며 논리 디스크는 하나의 파티션이나 볼륨과 같은 논리적인 부분을 말하는 것이다.
2.2 Python 디스크 열기
Python을 통해 이러한 물리 디스크나 논리 디스크에 접근하는 방법에 대하여 알아보자. Python에는 기본적으로 open(filename, type) 함수가 존재하고 있다. 그렇다면 어떻게 이러한 시스템적인 부분에 접근하는가? 아래의 그림을 보자.

그림 4. Python – open()
* 여기서 CMD를 열 때Administrator 권한으로 열어야 권한 거부가 생기지 않는다.
이렇게 Python에서 Drive에 접근하고자 할 땐 '\\\\.\\Drive'와 같이 나타내어야 한다. 이는 원래 \\.\Drive 인 것을 나타내기 위해 \를 두 번씩 표기하여 주는 것이다. 만약 두 번씩 하지 않으면 하나는 생략된 결과로 Python은 인식하게 된다. 접근 모드는 'rb'로 바이너리를 읽기 모드로 여는 것이다.

그림 5. Python – read()
제대로 물리 드라이브를 읽는 것을 확인할 수가 있다. 그렇다면 물리드라이브엔 어떻게 접근을 해야 할까? 의문을 가질 수가 있다. 결국 최종적인 목표는 $MFT를 수집하는 것임을 잊지 말자. NTFS에서 부팅 가능한 영역을 MBR에서 찾아서 가는 것이 어찌 보면 부팅 과정처럼 정도의 길이라 할 수가 있다.

그림 6. Python – 논리 디스크 열기
하지만 바로 논리 디스크로 접근하는 방법이 있다면 굳이 MBR에서부터 부팅 가능한 영역을 찾는 번거로움을 감수하고 싶지는 않을 것이다. 위의 그림과 같이 \\\\.\\ 뒷 부분에 열고자 하는 논리 디스크 'C:'와 같이 입력을 해주면 된다. 읽은 부분에서 NTFS 라는 그림 3에서 확인했던 문자열이 올바르게 출력되는 것을 확인할 수가 있다.
2.3 MBR 구조
물리 디스크 영역은 앞 부분에 MBR(Mater Boot Record)가 있다. 코드 영역엔 부팅을 하기 위한 코드들이 포함되어 있으며, 붉게 표시한 부분은 바로 파티션 테이블로 64 Byte를 차지하고 있는 것을 확인할 수가 있다. 전체적인 구조는 아래와 같이 나타난다.

그림 7. MBR
코드 영역은 별도의 구조가 없이 코드들로 이루어져 있지만 파티션 테이블의 경우에는 구조가 있기 때문에 그 구조에 맞게 해석을 할 수가 있어야 한다. 파티션 테이블은 부팅 가능한 디스크를 나타내기 위한 부분으로 아래의 구조와 같다.

그림 8. Partition Table
여기서 중요한 것은 바로 앞 부분의 1바이트이다. Boot Flag로 부팅이 가능한 파티션인지를 나타내는 값으로 0x80은 부팅이 가능하다는 것을 뜻하며 0x00은 부팅이 불가능함을 뜻한다. 파티션 타입의 경우 어떤 타입(FAT, Unix, NTFS 등)을 나타낸다.
그렇다면 부팅 가능한(Boot Flag = 0x80) 파티션이 있다면 그 위치는 어떻게 알 수 있을까? 예전엔 CHS Address를 사용했지만 점차 용량이 커지므로 표현의 한계가 있기에 현재는 LBA를 통해 해당 운영체제의 시작 지점을 알 수가 있다. 여기서 LBA란 Local Black Area의 약자로 흔히 섹터라 표현할 수가 있다. 위 그림 8의 Starting LBA Address란 결국 몇 번째 섹터에 운영체제가 시작하는 지 포함되어 있음을 의미한다. 이를 직접 확인해보자.

그림 9. HxD Partition Table
위의 그림은 실제 내 PC의 파티션 테이블이다. 각 색에 맞게 4개의 파티션이 나타나 있는 것을 확인할 수가 있다. 세 번째 파란색 부분을 보면 부팅 플래그가 0x80으로 부팅이 가능함을 나타내며 7912000 LBA에 운영체제가 시작함을 나타낸다.
* 참고 : 섹터의 크기는 512 Bytes이므로 해당 LBA에 512를 곱해 Offset을 알 수 있다.
단, 윈도우 7부턴 윈도우를 설치할 때 시스템 예약 파티션이 나뉘어 지는데, 해당 파티션은 BitLocker 암호화를 위한 예약된 공간이다. 특이한 점은 이전 XP와는 다르게 부팅 플래그가 바로 이 시스템 예약 파티션에서 설정이 되어 있다는 점이다. 다시 말해 위 그림 9의 부팅 플래그 0x80으로 되어 있는 부분이 시스템 예약 파티션이란 것이다. 정확한 이유는 알 수가 없지만, BitLocker 암호화는 지정된 보호 기능을 위해 동작하는 것으로, 해당 부분을 보호하기 위하여 먼저 이 곳으로 부팅이 되는 것이 어찌 보면 당연한 것이다. 컴퓨터의 전원을 켰을 때 장치에 이상이 없는 것을 POST에서 확인하는 것과 유사하다고 생각하자.
그렇다면 그림9에서 NTFS는 어디에 있는 것일까? 바로 네 번째 부분에 존재하고 있다. 파티션 타입번호(0x07)을 통해 확인하거나 해당 LBA로 직접 가서 확인하는 방법이 있다. 물론 시스템 예약 파티션을 없애면 바로 NTFS로 부팅 플래그가 설정 될 것이다. 만약 파티션이 5개 이상이라면 MBR에 더해 EBR로 관리를 하는데 이는 파티션 테이블 부분에 EBR로 가는 16 Bytes 구조가 생기며 해당 LBA로 이동하면 다음 EBR과 자신이 가리키는 파티션의 LBA를 가지고 있다.
3. NTFS
2장의 과정을 통해 MBR을 통해 부팅 가능한 파티션과 해당 파티션의 위치를 찾아가는 방법에 대하여 알아보았다. HxD로 '물리 디스크'로 디스크를 열었지만 이 방법을 통해 NTFS가 있는 '논리 디스크' C:와 같은 부분을 찾을 수가 있다.

그림 10. 논리디스크 찾기
이제 본격적으로 NTFS에 대하여 알아보자. Python을 통해선 2장의 과정이 없이 바로 C:와 같은 논리 디스크를 열 수 있음을 다시 한번 기억하자. 이제부터 다룰 내용은 NTFS의 구조에 대한 것으로 필수적으로 알아야 할 내용들을 주로 다룰 것이다.

그림 11. NTFS 구조
위 그림은 NTFS에 대한 전체적인 구조를 나타낸 것이다. VBR을 시작으로 MFT가 존재하고 있으며 그 후 각 파일에 대한 Data가 존재하고 있는 Data Area가 있다. 이들에 대하여 알아보기 전에 클러스터(Cluster)에 대하여 간략히 설명하고자 한다.
디스크는 기록을 할 때 Sector 단위로 한다. 하지만 NTFS 운영체제는 Cluster 단위로 기록을 하는 것으로 이 두 사이에 차이가 난다. 이러한 Cluster Size는 볼륨의 크기에 따라 주로 결정되며 기본적으로 2GB이상이라면 Cluster Size는 4 KB이다.
3.1 VBR
VBR은 Volume Boot Record의 약자로 해당 볼륨의 부팅을 위한 영역이다. 여기서 우리가 주로 보아야 할 부분은 바로 보라색으로 나타나있는 BPB 부분이다. 해당 부분엔 많은 시스템에 대한 많은 정보들이 포함되어 있다. VBR의 구조는 아래의 그림과 같다.

그림 12. VBR 구조
BPB엔 섹터의 크기나 클러스터의 크기를 포함하고 있으며 이 문서에서 가장 중요하게 다루는 MFT의 시작 위치가 있다. 그렇기에 이 부분의 몇 가지 항목만 올바르게 해석할 수 있다면 된다.

그림 13. BPB 구조
우선 Bytes Per Sector와 sec per Clus라 되어 있는 부분은 각 각 섹터의 크기와 클러스터의 크기를 나타낸다. 만약 사용자가 그 값을 윈도우를 설치할 때 지정해주었다며 다를 수 있으므로 반드시 저 부분의 값도 확인을 해야 한다.
그 다음 확인해야 할 중요한 사항은 바로 0x30에 위치한 Start Cluster for $MFT로 MFT의 첫 번째 Entry가 시작되는 클러스터의 번호를 담고 있다. 아래 예에선 MFT의 시작 위치가 C0000 Cluster임을 확인할 수가 있다. 따라서 해당 오프셋은 클러스터의 크기인 8 섹터와 섹터의 크기 512Bytes를 곱해주면 된다. 따라서 0xC0000000이 해당 오프셋이라는 것을 알 수가 있다.

그림 14. Start Cluster for $MFT
해당 오프셋으로 이동하면 MFT의 Signature인 'FILE' 문자열을 확인할 수가 있다. 따라서 올바르게 값을 해석했다는 것을 알 수가 있다.

그림 15. $MFT Signature
3.2 VBR – Python
그렇다면 Python을 통해서 VBR을 접근해보자. 그 뒤 필요한 항목을 어떻게 설정해야 하는지 확인해보자. 우선 '논리 디스크' C:를 위 그림 6에서의 방법과 동일하게 열어보자.

그림 16. Python – open C:
여기서부턴 해당 디스크를 Bytearray를 통해서 읽을 것이다. 아까와 같이 올바르게 NTFS 문자열이 출력되는 것을 확인할 수가 있다. 이에 더해 한 가지 함수를 먼저 만들어보자. 만들고자 하는 함수는 Little Endian으로 되어있는 16진수 값을 10진수로 읽어 값을 반환해주는 함수로 이후에 계속 사용될 것이다.

그림 17. Python – LtoI()
VBR에서 우리가 알아야 할 값은 총 3개이다. 섹터의 크기, 클러스터의 크기, 그리고 마지막으로 MFT Entry의 시작위치이다. 이 3개를 알아야 이후에 MFT에 대하여 Python을 통해 분석을 올바르게 할 수가 있다.
섹터의 크기는 VBR에서 0x0B~0x0C에 위치해 있으며, 클러스터의 크기는 0x0D에 있는 것을 BPB구조에서 확인할 수가 있었고 MFT는 0x30에 해당 클러스터의 값이 있다. 이제 이를 Python으로 입력해보자.

그림 18. Python – Sector
위의 그림과 같이 섹터의 크기는 512 Bytes(0x200)이며 클러스터의 크기는 8 섹터(4KB)임을 알 수가 있다. 이제 이 값을 가지고 MFT의 위치를 알맞게 해석할 수 있다. 아래의 그림을 보자.

그림 19. Python – MFT Offset
MFT의 첫 번째 Entry의 Offset이 0xC0000000임을 Python을 통해 해석할 수가 있었다. 이제 VBR에서 우리가 더 확인해야 할 항목은 없으므로 이제 MFT에 대하여 학습해보자.
4. MFT
VBR을 통해 MFT의 위치를 찾을 수가 있었다. MFR는 Master File Table의 약자로 NTFS에선 파일이나 디렉터리, 메타 정보들을 모두 파일의 형태로 관리하고 있다. 이러한 각 파일들의 위치나 속성, 이름, 크기 등의 메타 정보가 MFT Entry에 저장된다.
따라서 이러한 많은 정보들이 저장된 MFT를 통해 Forensic 조사에 있어서도 많은 유용한 정보들을 제공한다. 그렇기에 MFT에 대하여 이해 한다는 것은 많은 이점을 갖게 되는 것과 같다. MFT가 갖는 각 Entry에 대한 설명은 아래와 같다.

그림 20. MFT Entry 정보
많은 유용한 Entry들이 존재하지만, 모두 다루기엔 많은 분량이 나오므로 이 문서는 $MFT에 한정하여 설명할 것이며 추가적으로 필요한 내용에 한해서만 다룰 것이다. MFT Entry의 구조는 아래의 그림과 같다.

그림 21. MFT Entry 구조
MFT Entry 헤더가 오고 그 다음 Fixup Array가 나온다. 그 다음 가장 중요한 속성이 나오고 End Marker와 함께 뒤 부분은 사용되지 않는다. 이에 대하여 알아보자.
4.1 MFT Entry Header
MFT Entry 헤더는 Signature('FILE')로 시작하여 많은 정보들을 담고 있다. 이 문서는 MFT 수집 툴을 만드는 것이 목적이므로 많은 내용은 다루지 않을 것이다. 전체적인 구조는 아래의 그림과 같다.

그림 22. MFT Entry Header 구조
여기서 우리가 알아야 할 항목은 0x14에 위치한 'Offset to File Attribute' 항목이다. 이 항목은 속성이 시작하는 위치를 나타내주는 값으로 MFT 수집 툴을 만들기 위해선 이러한 속성 중 $DATA에 접근하여야 한다. 이에 대해선 좀 더 뒤에서 다룰 것이다.

그림 23. HxD - MFT Entry Header
위의 그림과 같이 0x14에 있는 값이 현재 0x38로 나타나는 것을 확인할 수 있다. 이는 0x38의 위치부터 속성이 시작된다는 것으로 그림에선 0x10이 존재하고 있다. 이는 $STANDARD_INFORMATION(이후 $SIA라 하자.)의 속성 ID 값으로 4.6에서 알아보자.
4.2 MFT Entry – Python
MFT Entry 헤더의 구조에 대하여 알아보았다. 이제 이를 Python을 통해 접근하는 방법에 대하여 살펴보자. 우선 우리는 그림 19에서와 같이 VBR을 통해 MFT의 첫 번째 Entry 주소를 알 수가 있었다. 이제 이를 통해 포인터를 이동시켜보자.

그림 24. Seek(MFT_Offset)
Seek()함수를 통해 파일을 읽을 위치를 이동 시킬 수가 있다. 우리는 현재 MFT Entry 정보를 읽을 것이므로 이전에 선언했던 mft_off 또는 그 위치 값인 0xc0000000으로 이동을 한 후 해당 부분을 512 Bytes 읽은 것이다.

그림 25. Attribute Offset
512 Byte를 읽은 다음 속성이 위치한 곳의 주소를 얻기 위하여 mft_attribute_off를 선언해주고 0x14-0x15의 값을 읽는다. 또 MFT Entry의 크기를 확인하므로 속성의 시작과 끝을 알 수가 있고, 이러한 속성의 데이터를 attr_off로 지정해놓은 것이다.
이제 속성의 시작 위치를 알 수가 있으므로 우리는 $DATA를 찾아야 한다. 이를 찾기 위해선 각 속성의 식별 값을 확인을 할 것이며 만약 $DATA의 식별 값인 0x80이 아니라면 해당 속성의 크기를 통해 다음 속성으로 넘어 갈 수가 있다.

그림 26. Find $DATA
여기서 3번째 라인을 보면 속성 값이 아닌0x0000(NULL)이나 0xFFFF(EndMarker)가 읽히면 해당 루프를 빠져 나오는 것을 확인할 수가 있다. 속성 식별 값이 0x80이 아니라면 해당 속성의 size를 구해 그 만큼을 건너 띄는 것을 아래의 2줄을 통해 확인할 수가 있다. 만약 0x80($DATA)이라면 아직 지정하지 않은 Data_parse()라는 함수를 호출해 $DATA 속성을 분석할 것이다. 이에 대해선 속성에 대하여 알아본 뒤에 다시 해보자.
4.3 Attributes
하나의 MFT Entry는 여러 개의 속성을 포함하고 있다. 이러한 속성엔 각 항목에 따라 유용한 정보들을 가지고 있으므로 이를 해석할 수 있어야 한다. 이러한 속성에 대한 설명은 아래의 그림과 같다.

그림 27. 속성 정보
많은 속성 항목들이 있지만 모두가 중요한 것은 아니다. 크게 가장 많이 사용되는 항목은 $SIA와 $FILE_NAME(이후 $FN), 그리고 $DATA 항목이다. 우선 이러한 속성의 공통적인 구조 먼저 알아보자.

그림 28. 공통 속성 헤더
속성의 구조는 거주 속성과 비거주 속성으로 나뉘어 지는데, 이에 대해 알기 전에 공통적을 포함되는 공통 속성 헤더에 대하여 알아보자. 구조는 위의 그림 25와 같이 되어 있다. 공통 속성헤더를 통해 어떠한 속성타입인지, 해당 속성의 길이가 얼마나 되는지, 만약 속성이 이름을 갖는다면 그 이름이 무엇인지 등이 있다. 여기서 속성 이름이란 $SIA나 파일 이름이 아닌, 속성 자체에 부여되는 이름을 뜻하는 것이다. 이러한 공통 속성 헤더 다음엔 거주 속성, 비거주 속성인지에 따라 다른 구조를 갖는다.
4.4 거주 속성 (Resident Attribute)
거주 속성은 해당 속성의 내용이 크지 않기에 MFT Entry 구조에 모두 담을 수 있을 때의 갖는 상태이다. 속성 내용을 모두 담을 수 있기에 다른 곳을 보지 않아도 되며, 그 내용은 거주 속성 헤더 뒤에 나타난다. 이러한 거주 속성의 구조는 아래의 그림과 같다.

그림 29. 거주 속성 헤더
속성 내용의 크기와 속성 내용의 위치, 인덱스 플래그, 마지막으로 속성의 이름이 있다면 그 속성의 이름이 나오며 없을 경우 바로 속성 내용이 나온다. 아래의 그림은 $MFT의 속성 부분을 나타낸 것이다.

그림 30. HxD - 거주 속성
공통 속성 헤더를 제외하고 0x48부터 거주 속성 헤더가 존재하는 것을 확인할 수가 있으며 해당 속성은 이름이 존재하지 않기 때문에 바로 뒤에 속성내용이 따라오는 것을 확인할 수가 있다. 이렇게 거주 속성의 구조에 대하여 확인할 수가 있으며, 이러한 거주 속성은 대부분의 $SIA와 $FN에서 나타난다.
4.5 비거주 속성 (Non-Resident Attribute)
속성 내용이 너무 커진다면 그것을 한곳에 모두 담을 수가 없다. 이러한 상태가 바로 비거주 상태라 하게 되며 이 경우 별도의 클러스터를 할당하여 그 곳에 내용을 담아 놓는다. 아래의 그림을 통해 구조를 확인해보자.

그림 31. 비거주 속성 구조
공통 속성 헤더가 나온 뒤 VCN이나 런리스트, 속성 내용의 크기, 속성 이름과 속성내용 등 관련된 내용들이 기록되어 있다. 이 항목들 중 자세히 알아볼 내용은 런리스트에 관한 내용이다.
비거주 속성은 속성 내용이 크기 때문에 외부 클러스터에 해당 내용들을 담고 있다. 하지만 이러한 클러스터들이 모두 연속적으로 존재할 수는 없기에 이러한 클러스터들에 대한 정보를 담고 있는 런리스트가 필요하다. 즉, 런리스트는 속성 내용을 담은 클러스터가 어디에 위치하였는지를 알려주기 위한 것이라 할 수 있다.

그림 32. Run List
런리스트를 해석하는 방법의 위의 그림과 같다. 첫 바이트를 읽어 일의 자리 수와 십의 자리수로 나눈다. 그 다음 일의 자리 수만큼 뒤의 바이트를 읽고 이것이 해당 클러스터의 길이가 된다. 십의 자리 수만큼 바이트를 이어 읽으면 해당 클러스터의 위치 값을 알 수가 있다. 이해하기 쉽게 직접 해석해보자.

그림 33. Run List
위의 그림은 내 PC의 MFT Entry 중 비거주 속성의 런리스트를 나타낸 부분이다. 검은색 동그라미가 첫 바이트이며, 붉은 색은 런의 길이, 파란 색은 런의 위치를 나타내기 위해 표시해놓은 것이다.
첫 번째 런의 첫 바이트는 '33'이다. 이를 십의 자리와 일의 자리로 나누면 십의 자리는 각 각 '3'이 된다. 따라서 둘 다 3바이트씩 읽은 것이다. 이를 해석하면 C00000 클러스터에서부터 C820개의 클러스터가 할당되어 있음을 나타내는 것이다.
두 번째 런은 앞과 유사하므로 생략하고 세 번째 런을 보자. 십의 자리가 '4' 일의 자리가 '2'임을 알 수가 있다. 따라서 런 길이는 2바이트를 읽어 0x308이며 런 위치는 4바이트를 읽어 124727B 클러스터이다. 이렇게 런리스트를 해석하면 비연속적으로 저장된 데이터를 올바르게 찾아갈 수가 있다.
이를 찾아갈 때 고려해야 할 것은 2번째 런부턴 앞의 이전의 런위치를 더해야 한다는 것이다. 2번째 런을 예로 들면 런 위치가 57E23D 번째 클러스터에 있음을 알 수가 있는데, 정작 57E23D 클러스터를 확인해보면 올바르지 않게 되어 있다. 올바르게 찾아가기 위해선 57E23D에 C0000을 더해야 한다. 따라서 63E23D 클러스터에 올바른 속성 내용이 위치하고 있다는 것이다.
이러한 비거주 속성은 보통 파일의 크기가700Bytes 보다 더 클 경우에 속하게 되며 이보다 작을 경우엔 거주 속성이 된다. 주로 $DATA의 경우 비거주 속성을 띄는 경우가 많으며 우리가 목적으로 하는 $MFT 또한 이러한 비거주 상태에 속하므로 클러스터 런을 올바르게 해석할 수 있어야 한다
4.6 Attribute - $SIA, $FN, $DATA
$STANDARD_INFORMATION
$SIA는 $FN과 같이 모든 MFT Entry에 기본적으로 포함되는 속성으로 파일의 시간 정보와 파일에 대한 정보 등이 기록되어 있다. 전체적인 구조는 아래와 같다.

그림 34. $SIA 구조
$FILE_NAME
$FN은 해당 MFT Entry가 가리키고 있는 파일에 대한 이름을 포함하여 $SIA에도 있었던 시간 정보들이 존재한다. 하지만 $SIA의 시간정보에 비해 상대적을 변경 되는 경우가 적다. 이에 대해선 나중에 더 자세히 학습하자. $FN의 구조는 아래와 같다.

그림 35. $FN 구조
$DATA
마지막으로 알아볼 $DATA 속성에 대해선 조금 더 자세히 알아보자. 위의 두 가지 항목은 파일에 대한 정보를 나타내는 것이었다면 $DATA는 해당 파일의 실제 내용으로 앞의 두 개와 마찬가지로 중요한 속성이다. 우선 구조를 먼저 살펴보자.

그림 36. $DATA 구조
구조가 상대적으로 매우 단조로워 보인다. 만약 $DATA 속성의 크기가 작다면 속성 헤더(공통헤더와 거주속성헤더) 뒤에 바로 속성 내용이 나오게 된다. 하지만 만약 속성의 크기가 커지면 비거주 상태가 되어 위에서 살펴본 바와 같이 클러스터 런을 통해 속성 내용을 관리한다.
만약 $DATA 속성이 2개라면 어떻게 될까? 이것이 바로 ADS다. 기존의 메인 스트림 외에 대체 스트림이 하나 더 주어지는 것으로 이 경우 반드시 속성 이름이 주어진다. 이를 통해 추후에 $UsnJrnl:$J를 분석할 때 참고할 수가 있을 것이다.
이번 문서의 목적은 Python을 통해 $MFT를 수집하는 것이므로 일반적으로 크기가 큰 $MFT가 많기 때문에 대부분 비거주 상태에 있다. 따라서 이러한 $DATA의 클러스터 런을 잘 해석할 수가 있어야 할 것이다.
4.7 $DATA - Python
올바르게 속성 식별 값 0x80($DATA)를 찾았다면 이제 해당 부분을 분석하여 정보를 추출을 위한 정보를 알아내야 한다. 우선 Runlist의 위치와 해당 버퍼를 담아보자. 아래의 그림에서와 같이 $DATA의 구조를 읽어 런리스트의 위치와 런리스트부터의 버퍼를 담고 있는 것을 확인할 수가 있다.

그림 37. $DATA 분석 – Python
$MFT의 $DATA 속성의 경우 비거주 속성을 가질 수 밖에 없다. $MFT가 700바이트 이하의 크기를 갖기는 많이 어렵기 때문이다. 런리스트를 반복문을 통해 분석하기 전에 필요한 변수들을 먼저 선언해주자.

그림 38. 변수 선언
Count와 tmp, calc, add_offset 등은 반복문에서 대부분 첫 번째 런을 위하여 존재하는 것이며 clu_size와 clu_off, tmp_size와 tmp_offset은 런을 해석한 결과를 담기 위해 미리 리스트(배열)을 선언해놓은 것이다. 이제 반복문을 통해 분석을 진행해보자.

그림 39. 반복문 – 분석
2번째와 3번째 라인은 이전에 선언해놓은 tmp='00'을 십의 자리와 일의 자리로 나누어 계산을 진행하는 것으로 이후에 tmp가 런의 첫 바이트를 읽어 다시금 자리 수를 나누기 위함이다.
6번째 라인이 런의 첫 바이트틑 읽는 것으로 이후에 clu_size와 clu_off를 위해 몇 바이트씩 읽어야 하는지 나타내기 위해 존재한다. 그 후 tmp_들로 인하여 해당 바이트의 값을 읽고 있는 것이다. 그리고 add_offset을 통해 4.5에서 살펴본 것과 같이 클러스터 런의 오프셋을 더하기 위한 부분이다. 이렇게 반복문이 0x00을 만나 빠져나오면 tmp_에 담겨있는 값을 다시 정리하여야 한다. 이를 위한 코드는 아래와 같다.

그림 40. Tmp 정리
이전에 tmp에 담겨있는 것을 정리하기 위해 각각 size와 offset을 선언해준다. 그 후 반복문을 통해 클러스터 단위가 아닌 바이트 단위로 나타내기 위하여 tmp의 값에 초반에 구했던 sec과 clu를 곱해준다.
이렇게 얻어진 값을 통해 기록하고자 하는 파일을 연다. Seek() 함수를 통해 해당 클러스터의 오프셋으로 이동해 사이즈만큼 읽고 이를 기록한다. 이렇게 런의 수만큼 반복이 된다. 최종적으로 완성된 코드를 실행하면 결과는 아래의 그림과 같다.

그림 41. 실행 결과
5. 정리
간단하게 $MFT 수집 도구를 만들고 싶었지만, $MFT를 수집하기 위해선 결코 간단한 지식을 가지고는 수집할 수 없겠다는 것을 여러 번 느끼는 계기가 되었다. 이해했다고 생각했던 것들이 코드를 통해 직접 해보려 하니 낯설기도 하고 더 어렵게 느껴지기도 하였다.
그래도 직접 NTFS를 공부하면서 만들어보고자 했고, 결국 만들었음에 매우 흡족하다. 이후엔 $LogFile과 $Usnjrnl:$J까지 한번에 수집해주는 도구를 제작해보고자 한다. 이를 위해선 더 많은 것을 공부해야겠지만 분명 재미있는 공부가 될 것이라 생각한다.
참고 자료
해킹대회문제로 배우는 파일시스템.pdf
humanistcpu.blogspot.kr/2013/10/hxd-mbrmaster-boot-record.html ; HxD MBR 구조
분석
cappleblog.co.kr/40; MBR 구조
cappleblog.co.kr/590; MBR 해석
forensic-proof.com/archives/2975 ; 시스템
예약
파티션
관련
내용
forensic-proof.com/archives/357
forensic-proof.com/archives/431
http://home.sogang.ac.kr/sites/gsinfotech/study/study1702/Lists/b10/Attachments/17/20131212_%EC%B9%A8%ED%95%B4%EC%8B%9C%EC%8A%A4%ED%85%9C%EB%B6%84%EC%84%9D.pdf
http://ntfs.com/ntfs-partition-boot-sector.htm
(FP) NTFS.pdf
forensic-proof.com/archives/584
































 NTFS&Python-$MFT수집.pdf
NTFS&Python-$MFT수집.pdf




























