


0. Before
이 문서를 번역하는데 있어 해당 문서가 2006년임을 감안하여야 한다. 이 때에 비하여 현재 9년이나 흐른 시점이므로 당시보다 메모리 포렌식이 더 발전하였기에 너무 아래의 글을 읽는데 있어 이를 감안하여야 한다.
0. Abstract
휘발성 메모리에 대한 조사는 상대적으로 새로운 분야이지만 그만큼 포렌신 분야에 있어서 중요한데 이는 이제 범죄자들 또한 포렌식에 대하여 인지를 많이 하는 추세이며 대상 컴퓨터의 하드 디스크에 대한 접근 없이 범죄를 저지를 수 있기 때문이다. 이는 전통적인 "Pulling the plug" 침해 대응 연습이 범죄의 유일한 증거를 파괴할 수 있다는 것이다.
메인 메모리의 콘텐츠를 수집하는 몇개의 방법들이 존재하는 반면에 의미 있는 방식으로 이러한 데이터를 해석할 수 있는 것은 몇 존재하지 않는다. 이러한 요인의 이유 중 하나는 바로 현대 운영체제의 가상 메모리 시스템의 복잡한 추상화이다. 이는 겉보기에는 하나의 프로세스에 속하는 데이터가 하드디스크나, 물리메모리의 전체 범위를 가로질러 임의의 방법으로 분산되어 질 수 있다는 것이다.
이 문서에서는 필요한 데이터를 담고 있는 커널 구조와 어떻게 물리메모리와 가상메모리 공간이 메모리가 맵핑되고 변환되는지를 포함하는 가상 메모리 시스템, 그리고 메모리를 수집하거나 분석할 수 있는 툴들에 대하여 초점을 맞추고 있다.
1. Introduction
Motivation and Intent
시디롬이나 하드디스크와 같은 비휘발성 저장장치의 데이터를 수집하거나 조사하는 방법에 대해서는 문서화가 잘 되어 있는 반면에 메인 메모리와 같은 휘발성 저장장치에 대한 가이드 라인은 여전히 부족하다. 몇 가이드 라인은 휘발성 메모리 수집을 완전히 무시하며 대신에 하드 디스크의 데이터 손실을 방지하기 위해 즉시 장치의 전원을 종료할 것을 제안하였다. 다른 몇 가지 가이드 라인의 경우에는 휘발성의 순서에 메모리에서부터 마지막엔 비휘발성 데이터 등을 따라서 데이터를 수집해야한다고 제안한다.
하지만 이러한 가이드라인은 어떻게 이러한 수집이 진행되어야 하는지를 자세하게 보여주지는 못한다. 게다가, 메모리 이미지가 취득된 이후 현재 어떻게 이러한 이미지가 분석되어야 하는지에 대한 규범적인 가이드라인이 존재하지 않는다. 많은 조사자들은 텍스트 검색을 하거나 이미지와 같은 파일을 찾기 위해 카빙을 한다. 하지만 이러한 조사들이 텍스트에서 몇가지 흥미로운 것들을 생성할 수가 있지만, 이것들은 복구된 데이터가 저장된 컨텍스트를 보여주지는 않는다. 예를 들어 문자열 검색은 불법적인 인터넷 사이트에 대한 레퍼런스를 밝혀주지만 사용자의 브라우저 히스토리 전체를 나타내주지는 못한다.
비록 본격적인 메모리 분석 시스템이 사용되고는 있지만 현재 프로세스의 가상 주소 공간을 다양한 방법으로 매꿀 수 있는 도구들이 현재 나타나지 않았다. 그러므로 이 문서의 초점은 어떤 데이터가 저장되어 있는지, 어디에서 복구를 할 수 있는지에 대하여 조사하는 것이며 가상 메모리 시스템을 상세히 조사할 것이다.
Overview
이번 장에서는 이 문서의 연구 단계에서 사용되었던 툴과 방법에 대하여 설명할 것이며 2 장에서는 윈도우 메모리의 몇가지 구조와 유용한 정보를 찾기 위해 어떻게 분석되어야 하는지를 설명할 것이며 3장에서는 윈도우 메모리 이미지로부터 정보를 어떻게 복구하는지를 보여주며 윈도우 가상 메모리 시스템에 대하여 설명할 것이다. 이는 가상주소와 물리주소, 페이징 시스템의 조사를 포함하며 어떻게 가상주소 공간을 조종하는지에 대해서도 설명한다. 4장에서는 메모리 수집을 위하여 사용되는 도구들의 측면에서 메모리 수집 프로세스에 대해 언급할 것이며 이미징 간에 발생할 수 있는 이슈와 문제에 대해, 그리고 가능한 솔루션과 대체 방법에 대하여 이야기 할 것이다. 5장에서는 현재 수집 간에 있어 생성되는 분석을 위한 방법을 설명할 것이다. 6장에서는 페이지 파일이나 메모리 이미지에서 주어지는 프로세스의 가상 주소 공간을 재구성하는 'vtop' 증거 개념 툴에 대하여 소개할 것이다. 여기에는 어떻게 툴이 동작하며 어떻게 더 나은 동작을 하는지에 대한 제안을 할 것이다. 마지막으로 7장에서는 이 문서의 연구결과에 대한 요약과 메모리 포렌식 분야의 더 나은 작업을 위한 추천을 할 것이다.
Methods And Tools
이 프로젝트를 위해 요구되는 연구의 핵심은 RAM이나 메모리 이미지에 있는 구조에 대해 상세한 집합이다. 이는 [13]으로부터 얻어진 시스템의 아키텍처의 지식과 'Debugging Tools for Windows'[41]을 통해 크래시 덤프의 디버깅, [55]'WinHex'와 디버거를 통해 오프셋과 주소를 수동으로 찾는 방법들을 조합하여 이루어진다.
아키텍처에 대한 충분한 지식을 갖고 있다면 메모리에서 구조에 대한 타입과 오프셋을 찾을 수가 있을 것이다. 이를 위해 메모리 이미지는 'dd'를 사용해 가졌으며 4장에서 소개할 방법인 'CrashOnCtrlScroll' 방법 사용한 크래시 덤프를 통한 테스트 시스템을 구성하여 사용할 것이다. 이러한 사항들은 'dd'에 의해 생성된 메모리 덤프가 불일치를 최소하기 위한 크래시 덤프와 유사함을 보장한다. 이 크래시 덤프 파일은 이를 분석할 수 있는 WinDBG[41]을 통해 열 수가 있다. 마이크로소프트로부터 심볼들을 다운받으므로 커널 구조는 'dt _eprocess'가 구조의 시작에 대한 데이터 필드의 주소를 포함하고 있는 _EPROCESS구조를 보여주는 것과 같이 'dt' 명령어를 사용하여 조사할 수가 있다. 이러한 하나의 구조의 시작 주소를 제공하므로 모든 연결된 다른 구조들은 그들의 오프셋의 주소를 읽으므로 찾을 수가 있고, 그들의 타입 또한 'dt' 명령어를 통해 찾을 수가 있다.
새로운 정보가 디버거로부터 얻어질 때마다 이러한 정보들은 WinHex를 통하여 메모리 덤프의 정보를 수동으로 복구하여 확인할 수가 있다. 구조에 있는 오프셋은 구조의 물리 주소를 이동시키고 오프셋을 더한 주소의 값을 읽으므로 확인할 수가 있다. 이 시점에서 이는 x86아키텍처는 데이터를 리틀 엔디언으로 저장하며 이러한 데이터의 값은 역순으로 읽어야 한다.
'vtop' 증거개념의 발전을 위해 코드 부분을 실행하고 모듈 전체를 리로딩 없이 테스트 할 수 있는 IDLE 파이썬 개발 환경을 사용한다.
두 가지 프로세스 뷰어의 영향을 테스트할때 'Process Viewer'[24]와 Process Explorer[48]을 사용할 것이다. 프로세스 익스플로어는 좀 더 디테일한 정보를 주지만 빠른 업데이트와 함께 실행중인 프로세스에서만 가능하다.
2. Windows Structures
윈도우즈 하에서 실행되는 각 프로그램들은 메모리에서 프로그램의 상태를 구체화 하는 프로세스로 할당이 된다. 프로세스가 실행되려면 프로그램이 실행된 이후 변경된 모든 데이터가 유지 되어야 하며 그것이 유지되는 프로세스의 구조안에 이러한 데이터가 있다. 현재 실행 중인 프로세스들의 목록은 Windows Task Manager를 통해 확인하거나 Sysinternals's의 Process Explorer와 같은 서드 파티 툴을 통해 확인을 할 수가 있다. 비록 이와 같은 도구들이 램의 내용을 변경할 수 있기 때문에 포렌식 환경에서는 프로세스를 확인하기에 좋은 방법이 아님에도 불구하고, 프로세스나 컴퓨터의 상태에 대해 RAM 으로부터 무엇이 밝혀 질수 있는지에 좋은 아이디어를 줄 수가 있다.
윈도우즈는 _EPROCESS 커널 구조에 각 프로세스에 대한 정보를 저장하며 이러한 대부분의 정보는 수집될 수가 있다. 모든 프로세스의 _EPROCESS 구조는 시스템 프로세스의 주소 공간에 저장되어 있으며 그렇기에 이러한 구조를 찾는 것은 메모리 분석에서의 첫 단계이다. 이는 이름, 타입, 각 구조의 오프셋등을 보여주기에, _EPROCESS 블럭의 베이스 주소는 알려져 있으며 이러한 값은 오프셋과 가산 값을 확인함으로써 판독할 수가 있다.
4GB 가상 주소 공간에서 첫번째 2GB의 가상 주소 공간은 프로세스가 쓰기 위하여 이용될 수 있으며 나머지 두번째 2GB(변경이 가능)는 시스템 메모리의 공유에 사용된다. 이는 0x00000000부터 0x80000000(0-2GB)까지 범위의 가상 주소를 찾는 것으로 쓰기 가능한 모든 메모리의 덤프를 구성할 수가 있다.
불행하게도 시스템 _EPROCESS의 가상 주소를 찾는 것은 매번 윈도우즈가 이를 로드하는게 다르기 때문에 어려운 작업이라 할 수 있다. mem_parser와 KnTList 툴들은 EPROCESS 구조 패턴과 특정 문자열을 찾으므로 이를 성공적으로 이를 했었다. XP에서 프로세스의 PDB는 항상 0x39000에 이으며 DirectoryTableBase 필드는 이 값으로부터 +0x018에 위치하고 있다. 또한 'ImageFileName'필드는 16바이트로 +0x174~0x183에 '시스템' 값을 갖고 있다. 그러므로 EPROCESS는 00039000 인스턴스를 찾으므로 밝힐 수가 있으며, 'System '(53 79 73 74 65 6D 00)으로부터 0x15C만큼 떨어져 있다. 이는 하나 이상의 결과를 만드는 것이 매우 어렵다. 또한 볼 수 있는 EPROCESS들은 아래에서 설명할 ActiveProcessLinks 필드를 통하여 확인할 수가 있다.
Process List
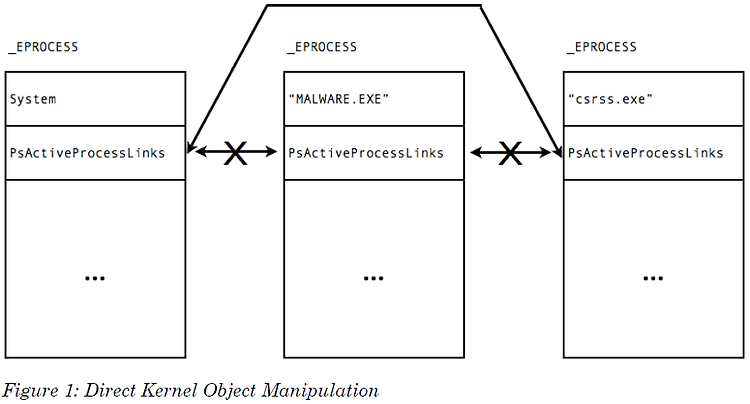
_EPROCESS에 대해 알아야할 첫번 쨰 사항은 시스템에서 실행 중인 다른 프로세스들 각각에 대응하는 _EPROCESS 블럭의 위치이다. 모든 프로세스들은 doubly-linked-list의 형태로 연결되어 있으며 그래서 'ActiveProcessLinks' 필드는 이전_EPROCESS(at +0x08C)와 다음 _EPROCESS(at +0x088)의 가상주소를 포함하고 있다. 'DirectoryTbleBase'를 제외한 모든 주소들은 변환이 필요한 가상 주소로써 주어진다(이에 대해서는 3장에서 다룰 것이다.). 실행 중인 프로세스를 찾는 이 방법을 사용할 경우 한 가지 단점은 악성코드가 자신을 다른 _EPROCESS들로부터 'Unlink'시킬 수 있다는 것이다. 이렇게 언링크된 프로세스는 분석가들이나 프로세스 뷰어에 보이지 않게 된다. 이를 위해, 악성 프로세스의 _EPROCESS 블록에서 앞뒤로 링크를 변경시키므로 가운데에 있던 자신은 잊혀지도록 한다. 이를 그림으로 보면 아래와 같다.

이러한 기법은 Direct Kernel Object Manipulation(DKOM)의 한 형태이며 이는 데이터를 숨기는 1차적인 방법중에 하나 이다. 이러한 문제를 해결 하기 위한 두 가지 방법이 존재한다. 첫 째로 RAM 이미지에서 _EPROCESS 블럭의 특성을 찾는 것인데, 비록 나은 기법들이 사용되면 오탐을 줄일 수 있기는 하지만 이는 어림짐작에 의존하기도 하며 오탐지될 확률이 높다. 두 번째 방법은 스레드가 실행 중일 경우 이는 'Dispatcher Ready Queue'라 불리는 큐에 담기므로,모든 스레드의 리스트를 얻기 위해 Windows thread queuing system를 분석하는 것이다. 스레드는 자신의 더 많은 정보를 찾을 수 있는 곳에 대한 자신 프로세스의 PEB 포인터를 포함하는 '_ETHREAD' 커널 오브젝트에 의해 나타난다. 불행중 다행스럽게도, 리버스 엔지니어링 없이 할 수 있도록 스레드 스케줄러에 대한 미약한 내용이나마 문서가 공개되어 있다.
Basic Process Details
실행 중인 모든 프로세스와 프로세스 블럭이 발견되면, 각 기본 정보들을 알아낼 수가 있다. 아래의 테이블은 유용한 엔트리를 몇 가지 보여준다. 여기서 세번째 항목까지는 _EPROCESS의 첫번째 필드인 PCB(_KPROCESS)의 항목과 같으므로 결국 EPROCESS에서도 바로 찾을 수가 있는 것이나 다름 없다.
Field Name |
Offset |
Description |
Direntory Table Base |
+0x018 |
페이지 디렉터리 베이스 * |
KernelTime |
+0x038 |
Time spent in kernel mode |
UserTime |
+0x03C |
Time spent in user mode |
UniqueProcessID |
+0x084 |
프로세스 PID |
ActiveProcessLinks |
+0x088 |
이전과 이후 EPROCESS의 APL 필드의 VA |
ObjectTable |
+0x0C4 |
VA of table of handles to objects |
InheritedFrommUniqueProcessID |
+0x14C |
부모 프로세스의 PID |
ImageFileName |
+0x174 |
executable file의 이름 |
Table 1: Usefil filelds in the _EPROCESS structure
* 페이지 디렉터리 베이스는 프로세스에 대해 가상 주소를 물리주소로 변환되어 사용되는 페이지 디렉터리의 물리 주소이며 이에 대해서는 3장에서 논한다.
( * 역 : 이러한 구조는 윈도우 버전에 따라 상이하기에 각 버전에 맞는 것을 찾아보아야 한다. )
Process Environment Block( PEB )
PEB는 프로세스 주소 공간에 위치하고 있는 프로세스 디스크립터의 일부이다. Windows XP 32비트 운영체제부터, 각 프로세스는 자신들만 사용할 수 있는 주소 공간을 갖는 것을 의미하는 32비트 가상 주소를 갖는다. PEB는 프로세스 주소 공간에 있는 많은 구조들의 주소를 포함하기 때문에 이는 매우 효율적이라 할 수 있다. PEB에 접근하는 기 위해서는 _EPROCESS블럭의 PDB와 _EPROCESS에 저장 되어 있는 PEB의 주소를 사용하여 가상 주소를 물리 주소로 변환하는 과정이 꼭 필요하다. 이러한 가상 주소를 물리주소로 변환하는 것은 3장에서 언급이 된다.
프로그램이 실행될 때, 실행파일의 사본이 메모리의 자신의 엔트리에 로드되며 이 주소는 PEB로부터 +0x008에 저장이 된다. 이 필드는 메모리 덤프로부터 카빙 될 수 있으며 실행 된 파일로 저장이 되고, 알려진 original과 함께 분석이나 비교할 수 있다.
추가로 또한 PEB는 프로세스가 사용 중인 모듈(DLL files), 파일이 가지고 있는 오픈 핸들, 프로세스 힙의 가상 주소, 공유 메모리와 코드 영역을 포함한다. 이러한 PEB의 필드들과 오프셋은 아래와 같이 정리할 수가 있다.
Field Name |
Offset |
Description |
ImageBaseAddress |
+0x008 |
실행 이미지의 가상 주소 |
Ldr |
+0x00C |
모듈 리스트를 포함한 구조의 VA |
ProcessHeap |
+0x018 |
프로세스 힙 시작의 VA |
Table 2: Useful fields in the _PEB structure
Interpretation
명백하게도 데이터는 의미 있는 방식으로 해석될 때에만 유용하다. 프로세스 리스트를 시작으로, 프로그램은 메모리 이미지가 만들어진 시점에 실행이 되었는지를 보여줄 수 있는데 이는 메모리 이미지를 수집하는 방법에 따라 의존적임을 유념해야 한다.
기본 속성 중 프로세스의 이름은 그 이름이 수상해보일 경우에는 더욱, 어떤 프로스세스를 나타내는지를 알려주기 때문에 유용하다. 하지만 이름이 신뢰할 수 있는 프로세스처럼 보일지 언정, 위에서 언급된 DKOM(Direct Kernel Object Manipulation)과 유사한 방법을 사용하여 진짜 존재를 변조할 수가 있다. 만약 프로세스가 신뢰할 수 있고 같은 이름(e.g cssrs.exe)으로 로드되거나 앞뒤의 'real' cssrs.exe의 링크가 숨겨지도록 수정되면, 'fake' cssrs.exe는 정교한 프로세스 리스팅을 사용하지 않는 한 유일한 엔트리로 나타날 것이다. 해당 프로세스가 시작되기 전에 침해 사건이 발생한 경우 'KernelTime'과 'UserTime'은 얼마나 오랫동안 프로세스가 시작되어있는지를 확인할 수가 있다.
또 PID와 PPID는 의심 되는 프로세스를 볼 수 있게 도와주는데 예로 explorer.exe의 자식 프로세스는 유저에 의해 키보드나 시작시 실행될 때 지역적으로 실행된다. 반대로 프로세스의 네트워크 서비스 PPID는 원격적으로 실행 될 수 있다. '_EPROCESS' 의 ObjectTable' 필드는 파일 및 레지스트리 키와 같은 열린 핸들을 가진 프로세스의 오브젝트를 나타내는 구조를 포함하고 있지만 이에 대해 조사를 하기에는 문서가 충분하지 않다. 마찬가지로 '_PEB'안 'Ldr'필드는 프로그램을 지원하기 위해 로드된 DLL 필드의 자세한 '_PEB_LDR_DATA'구조 주소를 포함하고 있다. 일부 경우에 이러한 것들은 증거 적인 가치가 있지만 이를 추가로 분석할 만한 증거가 불충분하다. 아마 이번 장에서 가장 가치있는 값은 바로 'DirectoryTableBase'인데 이는 가상 주소를 물리 주소로 변환하는데에 사용 될 수 있으며 이에 대해서는 3장에서 이야기 할 것이다.
PEB가 발견될 경우 이미지 파일이나 프로세스 힙과 같이 더 많은 분석을 할 수가 있다. 이미지 파일은 지정된 가상 주소의 콘텐츠를 읽으므로 메모리 덤프에서 카빙할 수가 있다. 이러한 파일의 길이는 아래의 테이블과 같이 EXE 헤더를 통해 추출해 낼 수가 있다.
Offset |
Field |
+ [0x4 - 0x5 ] |
The number of (512 byte) block in the file |
+ [0x2 - 0x3 ] |
The number of bytes of the final block to be read ( or all, if 0 ) |
Table 3: Offsets into the image file showing file size
파일이 추출되면 이는 생성된 해시를 통해 나타난 잘 알려진 것들과 비교 될 수 있다. 만약 이러한 것이 나타나지 않는다면 이는 테스트를 위해 디스어셈블하거나 그렇지 않으면 그것의 기능을 밝히도록 분석될 수가 있다.
PEB를 통한 이용 가능한 또 다른 증거는 프로세스 힙으로 이는 새로운 변수가 초기화 될때 프로세스에게 할당 되는 메모리 세그먼트로부터의 섹션이다. 그러므로 프로그램에 의해 저장된 어느 데이터도 이 공간에서 사용될 수가 있다. 하지만 각각의 응용프로그램은 그 데이터가 쓰여질 때 사용된 프로그래밍 언어나 코드를 컴파일할때 사용한 컴파일러, 컴파일에 쓰인 대상 플랫폼이나 디자인 된 프로그램에 따라 다르게 구성이 된다. 특정한 프로세스의 메모리를 분석하는 것은 이에 대한 자세한 지식이 필요하며 이를 할 수 있는 소프트웨어를 만드는 것은 종종 제한된 정보에 접근하거나 시간 둘 다 필요하다.
3. Windows Memory Management
현대의 모든 운영체제는 다른 프로세스에 속하는 데이터 접근의 위험이나 불필요성을 방지하고자 하면서 더 큰 주소 공간에 프로세스가 접근할 수 있도록 하는 가상 메모리 시스템의 형태를 갖고 있다. 윈도우 XP에 의해 사용되는 VM 시스템은 프로세스가 가상 주소 4GB 모두에 접근하는 것을 가능하게 하며, 페이징 시스템에 의한 실제 물리 주소에 대한 요청으로 가상 주소를 변환할 수 있다.
The Paging System
RAM의 과도함을 요구하지 않고 메모리의 전체 4GB를 프로세스가 위치하도록 하기 위해서는 각 프로세스는 페이징 시스템을 사용하여야 한다. 이 페이징 시스템 실제 물리 메모리 위치에 맵핑할 자신만의 가상주소를 허용해주며 이러한 페이징 시스템은 다음과 같이 구성이 된다. "각 프로세스가 유지하고 있는 페이지 테이블을 참고하는 1024을 포함하는 페이지 디렉터리, 각 페이지 테이블이 포함하고 있는 각 4096 주소를 참조하는 1024 페이지". 이는 4MB 전체 페이징 구조를 저장하는데 반해, 1024*1024*4096 이나 4G 가용한 주소를 줄 수가 있다. 32비트 가상 주소는 아래와 같이 3가지 파트로 나누어 진다.(예로 주소가 0x81291830)

이는 Page Directory에 10비트 인덱스와 Page Table에 10비트 인덱스, 그리고 Page에 12비트 인덱스를 허용한다. Page Directory Index는 사실 프로세스의 EPROCESS block에 저장된 Page Directory Base에 주어진 물리주소에서의 오프셋이며 페이지 테이블의 주소를 포함하는 정보를 가진 Page Directory Entry를 가리킨다. Page Table Entry의 물리주소는 PDE에 있는 주소와 프로세스의 Page Directory Base를 조합하므로 찾을 수가 있다. 마찬가지로, Page는 Page Table의 주소와 PTE에 있는 주소를 조합하므로 찾을 수가 있다. 마지막으로 바이트 오프셋은 데이터를 찾기 위해 해당 주소에 추가된다. 이러한 프로세스의 세부사항과 예외사항은 이후에 뒷부분에서 설명할 것이다.
Page Table Entries
Page Directory는 효과적으로 동일한 포맷을 가지는 PDE(Page Directory Entries)와 PTE(Page Table Entries)의 Page Table로 구성된다. 이들은 필요한 Page Table이나 Page 뿐만 아니라 각각 다른 유용한 정보로의 포인터까지 포함한다. 이에 대한 구조는 아래와 같다.

여기에는 세가지 비트가 있는데 [1-19]비트는 Page Table이나 Page에 대한 위치를 가리키는 포인터를 포함하며 bit [31]은 페이지가 물리 메모리에 액세스 할 수 있는지의 여부를 나타내는 'Validity Flag'이다. [20-30] 비트는 오직 페이지가 물리 메모리에 접근할 수 없을 때에만 유용하다(아래에서 이야기 할 것이다).
Page Faults and the Page-file
일부 경우에 어느 한 프로세스가 많은 양을 필요로 하거나 많은 프로세스가 동시에 실행되고 있을 수 있기에 프로세스는 물리(실제) RAM에서 사용할 수 있는 것보다 더 많은 메모리가 필요로 한다. 이런 경우, 메모리에서 덜 사용되는 페이지가 하드 디스크로 'Swapped out'된다. 프로세스가 메모리의 페이지에 대한 요청을 하면, 페이지는 RAM으로 'Swapped in'되며 다른 페이지가 스왑 아웃된다. 프로세스가 스왑 아웃 페이지를 요청하면, 'Page fault'가 생성된다. 이는 VM시스템이 PDE나 PTE의 포맷을 다르게 해석하도록 야기하며 대신 요청된 페이지의 page-file을 보고하도록 한다. page-file은 일반적으로 'pagefile.sys'라 불리며 각 드라이브의 최상단에 위치하고 있다. 하지만 여러 페이지 파일이 있도록 설정되어 있는지와 어디에 있는지를 확인해야만 한다. 페이지파일의 포맷은 매우 단순하며, 정확하게 메모리와 동일하게 처리될 수 있다. 또한 이는 물리주소로 사용되는 같은 오프셋에 의해 참조될 수 있는 연속적인 단순한 데이터이다.
페이지가 더이상 메모리에서 사용될 수 없을 때, 'invalid'가 되며 이에 따라 PTE나 PDE가 변경된다. 'invalid' PTE나 PDE는 항상 최하위 비트가 0으로 설정 되어야 하지만 약간 다른 PTE/PDE 포맷을 사용하는 각자들이 'invalid'가 되는 몇 가지 이유가 있다.
- Page File : 요청된 페이지나 페이지 테이블은 디스크로 스왑 아웃된다. 이는 아래와 같이 페이지파일 넘버[N]의 오프셋을 읽으므로 검색될 수가 있다.
- Demand Zero : 요청은 zero의 페이지를 필요로 함에 따라 그러한 요청은 0을 리턴함으로 만족될 수가 있다. 필드 [O], [T], [P], [N], [V]가 모두 제로이다.
- Transition : 요청된 페이지는 페이지 테이블이 마지막으로 업데이트 된 이후에 수정되었을 수가 있다. 이는 필드 [V]가 제로인 것을 제외한 유효한 PTE는 동일하다.
- Prototype : 요청된 페이지는 다른 프로세스와 공유될 수가 있다. 이 구조는 유효한 페이지로 동일하지만 이는 실제주소를 가리키지 않기에. 편의상 잘못된 주소로 간주될 수가 있다.

Address Translation
언급한 바와 같이 주소 변환은 가상 주소와 프로세스의 Page Directory Base(PDB)를 가지고 시작한다. 이러한 두 값을 제공하므로, 페이지 파일이나 메모리 덤프에 대한 엑세스와 주소를 가상 주소에서 물리주소로 변환할 수 있으며, 제공된 주소의 메모리에서 콘텐츠를 발견될 수 있다. 이 순서는 아래와 같으며 최상위 비트는 0으로 번호가 매겨진다. 이하의 설명이 도움이 되도록, 예제는 이러한 변수들을 가질 것이다.
VA |
PDB |
0x81291830 |
0x00039000 |
1. VA의 10비트(1000000100=0x204)를 갖고 각 PDE는 4바이트이기 때문에 0x4를 곱하여 0x810을 제공하므로 페이지 디렉터리 인덱스(PDI)를 복구할 수 있다.
2. 페이지 디렉터리의 물리주소를 제공하기 위해 PDI(0x810)을 PDB(0x39000)를 추가한다. = page directory(0x39810)
3. PDE(0x01222163)를 제공하기 위해 32비트(4바이트) 주소의 값을 읽는다.
4. Page Table의 물리주소는 PDE의 특정 비트의 상태에 의존한다. 만약 [31] 비트가 1일 경우 페이지는 유효하며, [0-19]비트는 0x1000(각 페이지는 4096바이트이다)과 곱해진 후 RAM의 물리주소로서 사용되고 읽혀질 수 있다. 만약 31비트가 0이면 페이지는 물리 RAM에 접근할 수가 없다. 이 경우는 다음과 같다.
- 만약 [0-20]과 [26-30]이 0일 경우 PTE는 'demand 0'이며 그렇기에 제로 페이지가 반환될 수 있다.
- [21]비트가 1인 경우 페이지는 공유되는 주소를 의미하며 이처럼 단순함은 'invalid'로 간주 될 수가 있다.
- 만약 [21-22]가 0이라면 Page Table은 디스크로 스왑 아웃되어있는 것이며 이는 [27-30]비트가 페이지 파일 번호로 주어지고 [0-19]비트가 페이지 파일의 오프셋으로써 주어지는 것을 의미하며, 이 오프셋을 위치를 읽는 것은 Page Table의 주소를 알게 한다.
5. VA의 [10-19]비트(1010010001=0x291)에 0x4를 곱하므로 가상 주소로부터 PTI (Page Table Index)를 복구할 수 있으며 이는 0xA44이다.
6. PTI를 4단계에서 읽은 Page Table의 값에 더한다. 계산을 하면 그 값은 0x1222A44가 된다.
7. PTE ( Page Table Entry : 0x011F2163)의 주소를 읽는다.
8. 4단계와 마찬가지로, 페이지의 위치는 PTE에 의존적이다. 유효한 페이지 비트[0-19]에 0x1000을 곱하고 이는 RAM 내 Page의 물리주소로 사용될 수 있다. 4단계와 같이 적용하지 않으면 페이지는 'invalid'가 된다. 예에서 PTE는 유효하며 이는 주소 0x11F2000을 가져온다.
9. 정확한 가상 주소의 물리주소를 얻기 위해서 가상주소의 마지막 12비트[20-31]에 의해 주어지는 바이트 오프셋을 더한다.
이러한 과정은 가상 주소에서 참조하는 물리주소를 제공하며, 물리 메모리 덤프나 페이지 파일의 데이터 조각을 나타내는 주소를 제공한다.
4. Memory Acquistion
디지털증거의 가이드라인에 따라 적어도 가장 휘발 적인 것부터 수집을 해야한다. 이는 사고 대응 팀이 해야할 첫번 째 것들 중 하나로 현장에서 실행중인 컴퓨터 RAM의 사본을 확보하기 위해 시도해야한다는 것이다. 하지만 이러한 생각의 문제는 가이드 라인이 의심되는 장치에 대해 모든 단계를 다루는 것이 아니라는 점이다. 이러한 룰의 완화를 위해선 추론과 이미징 기법의 영향이 더욱 고려되어야 한다.
(역: * 현재에는 당시보다 더 나은 툴들이 많이 나왔기에 툴에 대한 설명들은 번역을 하면서 제외 시켰다.)
Software Solutions
소프트웨어 메모리 이미저는 의심 되는 컴퓨터나 의심되는 컴퓨터 안에 이미 나타나는 소프트웨어(운영체제와 같은)를 실행한다. 첫째로, 몇 가지 소프트 웨어는 존재하고 있는 운영체제에 의하여 실행된다. 이는 운영체제가 잘못되거나 무책임한 결과를 제공하는 방식의 프로시저 호출을 야기할 수 있으며 그 결과로 얻어진 결과들은 결코 신뢰할 수가 없다. 두번째로, 어떤 데이터는 이미징 프로세스가 동작하는 동안에 항상 수정되는데 이는 심지어 가장 효율적인 메모리 이미저도 메모리에 로드되며 이는 기존에 존재하는 데이터를 대체할 수 있기 때문이다. 만약 오래된 데이터가 디스크로 스왑 아웃되면 아직 덮어지지 않았지만 더 이상 사용하지 않는 페이지는 삭제될 것이다. 이 문제는 매우 작은 메모리 이미저를 통해 완화될 수 있지만, 이 문제를 완전히 제거할 수는 없다. 메모리 이미징 프로그램은 메모리 이미지에 나타나며, 그러므로 조사시에 고려되어야만 한다.
또 다른 문제는 대부분의 소프트웨어 솔루션은 유저모드에서 실행되며 다른 실행 중인 프로세스들과 프로세서의 시작을 공유한다는 것이다. 그러므로 이들은 다른 프로세스들이 프로세서로부터 실행 시간을 인수하기 전에는, 이미징 프로세스가 동작하는 동안에 데이터 변경을 초래할 수 있기에 RAM 전체의 내용을 이미징 할 수가 없다. 마지막 문제는 유저 권한으로 실행되는 메모리 이미저가 없다는 것인데 이는 유저 권한으로 물리 메모리 전체에는 접근을 할 수 없기 때문이다. 이러한 접근할 수 없는 부분도 조사에 있어서는 항상 고려되어야 하며 중요한 증거가 이로 인해 손실될 가능성이 존재함을 인지해야 한다.
Hardware Solutions
최근 들어(역:당시 2006년) 소프트웨어 기반 수집을 대체하는 몇 가지 방법들이 제안되었다. 이러한 기법들은 수정 없이 RAM의 전체 내용을 카피할 수 있도록하는 DMA를 통해 메모리에 직접 접근하는 이점을 갖는다. 이에 더해, 매우 빠르게 복사를 할수가 있으며, 이는 리스크를 줄이며 이미징 프로세스가 동작하는 동안 데이터를 변화를 감소시킨다.
Hibernation
'Hibernation'은 휘발성 메모리를 디스크에 저장하는 것을 허용하므로 사용되는 시스템이며, 데이터의 영구적인 손실 없이 전원을 끄는 것을 가능하게 한다. 몇 가지 문서에서 볼 수 있듯이 유용한 정보들이 'hiberfil.sys'로, 시스템이 하이버네이션 상태가 될 때 해당 파일에 저장되어 있을 수가 있다.
또한 하이버네이션은 추가적으로 프로그램이 로드될 필요가 없기 때문에, 메모리의 내용을 수집하는데 유용하게 사용될 수가 있다. 하지만 불행하게도, 이에 관련된 몇 가지 문제가 있다. 첫째로, 시스템이 절전모드가 될 때 데이터는 'hiberfil.sys'에 쓰여진다. 만약 이 파일이 기존에 존재하면 덮어 씌워지기 때문에 기존의 파일은 제거된다. 둘째, 'Disabled'된 시스템에서 절전모드를 활성화 하기 위해선 추가적인 단계가 요구되는데 이는 데이터가 변화될 위험이 증가하도록 한다. 또 중요한 문제는 윈도우 XP의 하이버네이션 코드는 'ntldr'파일안에 포함되어 있는데 이는 공개되지 않은 소스로 철저한 테스트 없이는 하이버네이션의 결과가 무엇일지 확실하게 표시할 수가 없다는 것이다. 또한 이는 어떠한 데이터가 저장되어 있는지 명확하지 않지만, 마이크로소프트에 따르면 현재 사용 중인 페이지가 디스크에 기록되므로 절전모드에서 정상모드로 복귀하는 속도를 향상시킨다. 그리고 이들은 독점 압축 알고리즘을 사용하여 쓰여지기 전에 압축된다. 이는 압축 알고리즘과 파일 포맷이 하이버네이션 파일을 분석하고자 하면 이전에 밝혀져야만 한다는 것과. 잔여 데이터 메모리의 여유 공간을 분석하기 위한 기회가 없다는 것을 의미한다. 만약 이러한 문제들이 해결된다면 다음과 같은 사항들이 하이버네이션을 통하여 가능해진다.
hiberfil.sys 파일을 복사, 시스템을 절전모드로 전환, 디스크를 복사(클론), 절전모드일 때와 동일한 상태에서 시스템을 생성하거나 재개하는데 클론을 사용
하지만 이러한 단계를 실현가능하도록 하기 위해서는 하이버네이션 프로세스와 하이버네이션 파일의 포맷에 대한 더 많은 연구들이 필요하다.
5. Memory Analysis
의심되는 장치로부터 메모리 이미지를 획득했다면, 그로부터 추출될 수 있는 의미있는 정보들을 위해 분석을 해야만 한다. 최근까지(역: 2006년) 만약 메모리가 조사되지 않았다면 이를 종종 문자열이나 'foremost'와 같은 카빙 툴을 사용해 공통된 파일 타입을 찾고는 했었다. 앞서 언급한 바와 같이이러한 방법들은 몇 가지 유용한 정보의 조각들을 밝혀주지만 저장되어 있는 그 정보들의 내용은 손실되어있는 경우가 많다. 메모리 덤프 분석의 영역은 수집보다 새롭지만, 몇 가지 툴들이 개발되었다. 마이크로 소프트의 'Debugging Tools for Windows' 또한 특정 상황에서 메모리 분석에 사용할 수 있지만, 메모리 분석 툴 중 공개된 것으로는 'Memory Parser'와 'WMFT'이다.
이 문서에서 지금 까지 발표된 정보는 적어도 다음과 같은 작업이 자동화 툴을 이용하여 가능하다는 것을 보여준다.
- 가능한 자세하게 어드밴스 프로세스 Lister를 통해 실행 중인 프로세스에 대한 데이터를 보여준다.
- 프로세스를 로드하는 실행파일의 이미지를 복구할 수가 있으며, 이를 디스크로부터 원본과 비교하거나 더 상세히 분서할 수가 있다.
- 힙으로 부터 각 프로세스에 할당된 메모리 공간을 보여주며, 프로그램에 대한 상세한 지식과 시스템에 의해 분석하거나. 문자열이나 이미지를 찾을 수가 있다.
- 가능한 경우 페이지 파일을 통합하고 읽혀지는 각 프로세스의 가상주소 공간의 전 범위를 허용한다.
(* 역 : 툴에 대해서는 현대에 더 좋은 툴이 많기에 WIinDBG만 간략하게 언급을 하고 이외의 것들은 언급하지 않습니다.)
Available Tools
WinDBG
WinDBG는 Debugging Tools for Windows의 GUI컴포넌트이며 사용자가 실행 중인 시스템이나 시스템 크래쉬에 의해 생성되는 메모리 덤프를 분석할 수 있게 해준다. 명령어는 크래시 됐을 때의 시스템 상태의 특정 측면을 나타내기 위해 입력될 수 있으며, 조사될 프로세스에 사용가능한 심볼 데이터베이스를 제공한다. 운영체제에 대한 심볼들은 전역적으로 정의가 가능하지만 private 심볼들은 유저공간 프로그램에 의해 정의 될 수 없다. 크래시 덤프가 열리거나 분석될 때 선택할 수 있는 많은 명령어들이 존재한다. 이러한 명령어 중 가장 유용한 몇 가지는 아래와 같다.
Command |
Description |
dt [type] ([VA]) |
[type] 구조의 구성을 보여주며, 옵션으로 만약 구조가 시작하는 주소[VA]가 있다. |
!process 0 7 |
실행 중인 프로세스에 대한 가능한 모든 세부사항을 보여준다. |
!ptov [dirbase] |
[dirbase]에 의해 정의된 PDB를 가진 프로세스의 물리-가상 주소 맵핑을 보여준다. |
!vtop [dirbase] [va] |
[dirbase] 를 통해 [va]의 물리주소를 보여준다. |
Table 4: Useful WinDBG commands
이러한 명령어들은 커널 공간을 설명하는 핵심 값들을 제공하며, 이미지 파일이나 프로세스 힙과 모듈에 대한 주소와 같이 프로세스에 대한 몇 가지 정보를 제공한다. 하지만 WinDBG를 통해 덤프의 실행 이미지 파일을 복구할 수는 없다.
6. The 'vtop' Proof-of-Concept
( * 역 : 이번 장부터는 위의 개념들과는 별로 관련성이 떨어지기에 몇 부분만 번역하였다. 자세한 사항이 궁금하다면 원문을 보아야 한다. )
Intent
이 툴은 프로세스의 가상 주소 공간이 페이지 파일과 물리 메모리 덤프를 조합하므로 재구성 할 수 있음을 증명하도록 개발 되었다
Tools and Design
이는 단지 개념 증명을 목적으로 했기 때문에, 보통 모듈화, 규모화, 성능 및 요건이 개발 시간을 희생시켰다.프로그래밍 언어로는 파이썬을 선택되었는데, 이는 파일 핸들링과 같은 필요한 OS 함수들을 모두 지원하며, type이 함축되도록 허용한다. 또한 2진수와 10진수, 16진수를 변환하기에 편리하기 떄문이다. 'IDLE' 개발 환경을 사용하는 것은 실시간으로 코드가 쓰여지고 실행될 수 있음을 허락하며 새로운 함수들이 전체 시스템의 리로드 없이 테스트 될 수 있다.
Testing and Problems
이 프로그램은 오직 개념 증명이기에 철저하게 제품으로서 테스트 되지 않았다. 몇 가지 구조들은 예상되는 주소에서 출력되었고 심지어 이는 버그가 존재해도 기본적으로 작동하도록 나타났다.
프로그램의 첫번째 문제중 하나는 큰 파일을 읽을 때 발생한다. 파이썬에 대한 제한된 경험때문에 vtop의 첫번째 버전은 메모리 덤프나 페이지 파일 전체의 내용을 읽으려 시도하며, 긴 시간이 걸리지 않았은 것 뿐만 아니라 테스트 시스템의 스왑 파일이 충분히 크지 않다면 I/O 예외를 생성한다. 이 문제는 추후에 파일의 작은 부분이 한번에 읽힐 수 있도록 하는 seek() 함수를 사용하므로 극복하였다.
가장 큰 문제는 프로그램의 부분을 테스팅 하는 것이 어렵다는 것이다. 페이지 파일로부터 복구된 데이터가 어떤 결과가 나오는지 밝힐 수가 없기에 이것이 옳은 것인지를 확인할 방법이 없다. _EPROCESS 블러이나 이와 연결된 구조와 같이 확인 될 수 있는 모든 중요한 데이터 구조가 디스크에 페이징 되지 않고 오직 사용자 공간 프로세스들만 스왑 아웃된다. 이를 테스트하는 하나의 명백한 방법은 특정한 가상 주소에 특정한 데이터를 기록하는 프로그램을 제작하고, 프로세스가 디스크에 페이지 되도록 하며, 메모리나 페이지 파일을 수집한 후 지정된 데이터의 지정된 주소공간을 확인하는 것이다. 이 방법은 매우 어려우며, 시간 또한 많이 소요된다. 또한 이미 필자가 시도했지만 실패하였다.
Improvements
툴이 개념증명 상태 이후 개발된다면, 몇 가지 옵션들이 주어지면 더욱 유용할 것이다. 이러한 요소로는 특정 PDB를 지정하거나 I/O 파일이름과 명령어 라인의 주소 범위, 대화형 또는 구성파일 등이 있으며, 이들은 좀 더 사용자가 사용하기 쉽도록 할 것이다.
Applications
이러한 제약에도 불구하고 이 툴은 특정한 상황에서 유용할 것이다. 만약 특정 프로세스가 의심되는 경우, 재구성된 주소는 그 프로세스와 관련될 수 밖에 없는 결과들에 대한 지식과 함께 찾을 수 있게 할 것이다.
Reference
Nicholas Paul Maclean - “Acquisition and Analysis of Windows Memory” PDF
'Forensic > Theory' 카테고리의 다른 글
| NTFS File System (1) 개요 (0) | 2015.12.28 |
|---|---|
| KDBG Structure (0) | 2015.11.08 |
| How to Use Volatility (0) | 2015.10.14 |
| $UsnJrnl 분석 (1) | 2015.10.09 |
| Torrent Artifacts (0) | 2015.10.06 |




































