
Intro
리버싱을 하는 데 있어 흔히 "Art of Reversing is an API Hooking"이라는 말과 같이 API 후킹은 리버싱의 꽃이라 일컬어진다. 어떤 윈도우 응용프로그램을 개발하기 위해서 우리는 다양한 종류의 언어나 도구를 사용할 수가 있다. 이런 언어나 도구를 사용하여 개발하는 방법은 다르더라도 결국, 개발된 프로그램의 내부로 들어가면 윈도우 운영체제가 제공하는 API를 호출한다.
이러한 API는 사용자 영역뿐만 아니라 커널 영역에서도 Native API의 형태로 존재하기 때문에 API 후킹을 이해하는 것은 윈도우의 많은 부분을 조작할 수 있음을 의미한다. 따라서 이번 문서에서는 API 후킹에 대한 이해를 도모하며, 기본적인 후킹의 방법에 대해 이해하므로 다른 후킹 방법 또한 낯설지 않도록 하는 것이 목적이다.
단, 후킹을 진행하는 자세한 코드들은 포함하지 않고, 어느 부분을 어떠한 방식으로 후킹 하는지 중점적으로 살펴볼 것이다. 코드들의 경우 다른 좋은 소스가 많으므로 그러한 요소들을 찾아보면 좋을 것이다. 이제부터 API 후킹에 대해 알아보자.
Prior Knowledge
이번 장에서는 구체적인 API 후킹에 대하여 알아보기 전에 우리가 알고 있는 API가 무엇인지 다시 한 번 정리해보고 API 후킹의 기본적인 개념에 대하여 알아볼 것이다.
What is an API?
API란 Application Programming Interface의 약자로 단어 자체만으로는 무슨 뜻인지 이해하기 힘들다. 쉽게 말해 운영체제가 응용프로그램을 위해 제공하는 함수의 집합으로 응용프로그램과 디바이스를 연결해주는 역할을 한다. 좀 더 구체적으로 응용프로그램이 메모리, 파일, 네트워크, 비디오, 사운드 등 시스템 자원을 사용하고 싶더라도 이들에 대해 직접 접근할 수가 없다. 이러한 시스템 자원은 운영체제가 직접 관리하며 보안이나 효율 등 여러 면에서 사용자 응용프로그램이 접근할 수 없도록 막아놓았기 때문이다.
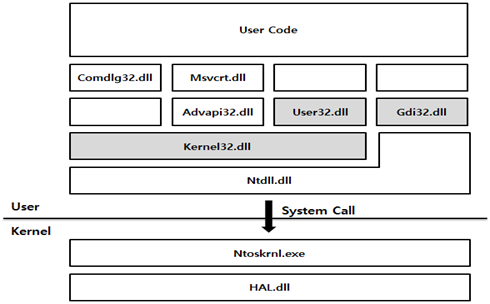
따라서 사용자 응용프로그램이 시스템 커널에게 이러한 시스템 자원의 사용을 요청해야 하며, 이 방법이 바로 MS 제공한 Win32 API를 이용하는 것이다. 즉 API 함수 없이는 프로세스, 스레드, 메모리, 파일, 네트워크, 레지스트리 등 시스템 자원에 접근할 수 있는 프로그램을 만들 수가 없다. 아래 그림은 32비트 Windows OS의 프로세스 메모리를 간략히 나타낸 그림이다.

그림 1. User Mode & Kernel Mode
실제 응용프로그램 코드를 실행하기 위해서는 많은 DLL이 로딩된다. 모든 프로세스는 기본적으로 kernel32.dll이 로딩되며, kernel32.dll은 ntdll.dll을 로딩한다. 바로 이 ntdll.dll의 역할이 사용자 모드에서 커널 모드로 요청하는 작업을 수행한다. 이러한 방식을 통해 시스템 자원에 접근할 수 있게 되는 것이다.
What is an API Hooking?
API 후킹에 관해 이야기하기 전에 후킹에 대하여 먼저 알아보자. 후킹이란 이미 작성되어 있는 코드의 특정 지점을 가로채서 동작 방식에 변화를 주는 기술이라 할 수 있다. Hook이라는 단어 자체가 낚싯바늘 같은 갈고리 모양을 가지는데 이를 통해 무엇인가를 낚아채는 것과 같이 컴퓨터에서도 무엇인가를 낚아채는 형태로 사용될 수 있다.
그렇다면 API를 후킹 한다는 말은 무슨 뜻일까? 바로 Win32 API가 호출되는 중간에서 가로채어 제어권을 얻어낸다는 것이다. 그렇다면 어느 시점에 가로채는지 궁금할 수가 있다. API 후킹에는 많은 기법이 존재하는데 이러한 분류가 주로 어떤 방식을 사용하는지, 그리고 바로 어느 지점에서 가로채는지에 따라 분류되므로 이에 대해서는 각 방식에서 자세히 알아볼 것이다. 기본적인 후킹의 개념은 아래의 그림과 같다.

그림 2. 정상호출과 후킹된 호출
정상적인 경우 A 단계가 진행된 다음에 B가 진행되어야 하지만, 후킹 된 호출의 경우 A 단계 다음에 B가 진행되는 것이 아니라 C가 진행된 뒤 B가 진행된다. 이를 통해 A의 요청을 조작하거나 특정한 조건에만 B가 실행되도록 조작할 수가 있다. 위와 같은 방식으로 API를 후킹 하면 그 함수의 기능을 사용하지 못하게 할 수도 있고 어떻게 사용하는지 감시만 할 수도 있다. 심지어 전혀 다른 내용으로 바뀌게끔 할 수도 있다.
User Mode Hooking
Windows에서는 크게 사용자 모드(User Mode)의 후킹과 커널 모드(Kernel Mode)의 후킹으로 나누어진다. 이번 장에서는 사용자 영역에서 어떻게 API 호출이 이루어지는지, 그리고 어떻게 이들을 후킹할 수 있는지에 대하여 알아보자.
IAT Hooking
3.1.1 IAT(Import Address Table)
IAT후킹은 IAT(Import Address Table)를 후킹 하는 것으로, IAT는 쉽게 말해 해당 프로그램이 어떤 라이브러리에서 어떤 함수를 사용하고 있는지를 기술한 테이블이다. 예를 들어, 어떤 프로그램이 Kernel32.dll의 GetDriveType API를 호출한다면 해당 API를 사용하기 위한 주소를 IAT에서 참조할 수 있다.

그림 3. PE View로 본 IAT
IAT 후킹은 바로 이 IAT에서 후킹하고자 하는 함수 주소를 내가 원하는 함수(이후 후킹 함수)로 교체하고, 후킹 함수에서 파라미터나 리턴 값을 조작하고 원래 함수를 호출하는 방법이 바로 IAT 후킹이다. 가장 쉬우면서도 안정적인 방법이라 일반적으로 자주 사용되는 후킹 방식이다. 그렇다면 일반적으로 API가 호출되는 상황을 보자.

그림 4. Sleep API
Sleep()를 호출할 때 직접 호출하지 않고 0x43B168 주소에 있는 값을 가져와서 호출한다. 0x43B168 주소는 해당 프로그램의 IAT 메모리 영역으로 0x76AE7990이라는 값이 존재하고 있다. 이제 이 값이 바로 해당 프로세스 메모리에 로딩된 Kernel32.dll의 Sleep 함수의 주소이다.
그렇다면 왜 0x40104F에서는 CALL 0x76AE7990이라 하지 않고 다른 곳을 참조하는 하여 접근하는 것일까? 이는 운영체제 버전이나, 어떤 언어, 서비스 팩이냐에 따라DLL의 버전이 다르며, 해당 함수의 위치가 달라지기 때문이다. 모든 환경에서 Sleep() 함수 호출을 보장하기 위해 컴파일러는 Sleep()의 실제 주소가 저장될 위치(0x43B168)를 준비하고 CALL DWORD PTR DS:[43B168]을 적어두기만 한다. 그 후 파일이 실행되는 순간 PE Loader가 0x43B168 위치에 Sleep() 함수의 주소를 입력해준다.
3.2.2 Hook
그렇다면 이러한 IAT의 개념에 대해 알아보았지만, 대체 이 부분 중 어느 곳을 후킹 해야 한다는 것인가 의문을 가질 수 있다. 위의 Sleep 함수를 예로, 사용자 모드에서 Sleep API가 호출되는 과정은 아래의 그림과 같이 나타낼 수 있다.

그림 5. 메모리에서 Sleep API
(A)는 3.2.1에서 이야기한 바와 같이 해당 함수를 사용하기 위한 주소 공간을 만들어 놓은 것이다. 이렇게 만들어 놓은 주소에 프로그램이 실행되며 PE 로더가 Sleep 함수의 주소를 채워 넣는다. 여기서 만들어진 주소 공간 43B168은 RVA 값이며, 이에 해당하는 파일 Offset은 39168이다. 39168은 바로 IAT 의 Sleep 함수가 위치한 Offset이다.

그림 6. Sleep API in IAT
만약 (A)에 존재하고 있는 값인 43B168을 다른 값으로 바꾸면 어떻게 될까? 직접 Sleep 함수를 호출하는 부분에 IsDebuggerPresent API의 IAT 주소를 넣어보자. 주소는 위 그림에서와 같이 Offset 39164이므로 이는 RVA 43B164가 된다. 이제 아래와 같이 코드를 패치해보자.

그림 7. 코드 패치
원래 Sleep()을 호출하던 부분에 IsDebuggerPresent()의 IAT 주소로 변경을 해주었다. 그렇다면 이제 위에서 언급한 바와 같이 PE 로더가 0x40104F에서 호출하는 함수의 주소를 0x43B164에서 참조하기 때문에 아래의 그림처럼 IsDebuggerPresent()가 위치하게 된다.

그림 8. 호출할 함수 주소 변경
이를 정리하자면, 프로그램이 사용하고자 하는 API를 호출할 때 해당 명령어에는 "CALL DWORD PTR DS:[IAT에 존재하는 해당 함수의 RVA]"로 나타내며, 프로그램이 실행되면서 실제 주소가 해당 DS:[RVA]에 올라오게 된다. 따라서 위와 같이 (A)를 후킹 하기 위해선 DS:[HookFunc]로 바꿔주어야 한다..
이번에는 (B)의 경우를 생각해보자. (A)는 프로그램이 실행되기 이전 파일의 형태에서 조작이 가능하였지만 (B)의 경우 파일이 실행되면서 43B168에 실제 Sleep API의 주소를 가지고 온다. 그러므로 (B) 부분은 파일이 아닌 프로세스일 경우에만 조작이 가능함을 알 수가 있다. 따라서 쉽게 DLL Injection과 같은 기법을 통해 프로세스의 메모리를 조작할 수 있지만, 이번 문서는 코드와 관련된 부분은 최대한 제외하고 원리를 이해함을 목적으로 할 것이기 때문에 필자는 디버거를 통해서 접근할 것이다.

그림 9. 함수 호출 - Debugger
위 그림을 보면 Sleep 함수를 호출할 때 43B168을 참조하며, IsDebuggerPresent 함수를 호출할 때는 43B164를 참고하는 것을 확인할 수 있다. 아래 덤프 영역을 보면 각각 해당하는 함수의 주소가 PE 로더에 의해 지정된 것을 확인할 수 있다. Sleep 함수가 가리키는 곳에는 76AE7990이 위치하며 다른 곳에는 76AEB0B0가 위치하고 있다. 해당 지점에는 각 함수의 실제 실행과 관련된 부분이 존재하고 있다. 따라서 이 위치를 변경하면 후킹을 진행할 수 있다. 만약 43B168(Sleep)에 76AEB0B0를 넣어주면 어떻게 될까?

그림 10. Sleep이 호출하는 주소 변경
위 그림처럼 분명 디버거는 Sleep()이라고 나타내지만 하단의 DS에서 가리키는 곳은 KERNEL32.IsDebuggerPresent 이다. 이를 통해 디버거 또한 IAT를 기준으로 주석에 나타내주는 것임을 알 수가 있다. 그렇다면 좀 더 심화 학습을 진행해보자. 흔히 코드 케이브(Code Cave)라 할 수 있는 방법을 여기에 적용해볼 수가 있다.
코드 케이브에 대해 간단히 설명하자면 해당 프로세스의 빈 공간에 사용자가 정의한 코드를 넣어준 뒤, 이 부분으로 프로그램이 전개되도록 하는 방식이다. 예제 프로그램에서 빈 공간은 Sleep이 호출되는 윗부분에 존재하고 있다. 따라서 Call 명령어를 통해 DS:[43B168]을 참조하게 되는데, 이때 43B168은 코드 케이브의 위치인 401023이 존재하고 있다. 401023에서 Sleep API의 인자로 사용되기 위해 스택에 저장되어 있는 값을 증가시키므로 흐름을 방해한다. ADD 명령 다음에는 원래의 기능을 수행하기 위해 조작되기 이전 값인 76AE7990로 점프를 해주면 된다.

그림 11. Code Cave를 사용한 후킹
이렇게 조작을 했는데 과연 제대로 프로그램이 동작할까? 당연히 제대로 동작한다. 이전 (A)에서는 IAT에 존재하는 다른 API로 변경하는 것만 진행했지만, 이번 과정에서는 인자로 전달되는 값을 직접 수정할 수가 있다. 이는 사용자로부터 입력 받은 값을 조작하여 특정한 함수의 흐름을 조작할 수 있는 것과 같이 다른 면에도 유용하게 활용할 수 있다. (B)에 적용한 방식은 (C)의 시작 부분을 JMP Hook_Address로 이동하여 유사하게 적용할 수 있다.
(C)의 경우 실제 함수의 명령어들이 위치하고 있다. 따라서 이 부분을 후킹 하기 위해서는 명령어를 조작하여야 하는데 어떻게 조작해야 할까? (C)의 내용은 밑에 그림과 같다. 자세히 보면 상단의 세 명령어의 OPCODE는 총 5 바이트이다. 바로 이 부분을 조작하므로 우리는 원하는 함수를 후킹할 수 있다. 아래의 그림을 보자.


그림 12. (C) 단계 원래 명령어와 조작된 명령어
Sleep() 함수의 원래 주소 7673A6B0의 명령어를 JMP 명령어로 변경한 것을 확인할 수 있다. 이렇게 변경된 Sleep()함수는 호출될 때마다 해당 부분으로 이동하게 되며 공격자가 의도한 대로 흐름이 변경될 것이다. 필자가 의도한 조작은 아래 그림과 같이 Sleep() 함수의 시간 값을 증가시킨 다음, 원래대로 코드를 복원하고 복원된 지점으로 이동하는 것이다.

그림 13. 조작 코드
이렇게 코드가 아닌 어셈블리로 조작한 것은 글을 읽는 사람들의 이해를 돕고자 진행한 것이다. 실제로 이렇게 하는 사람은 거의 없으며, 특히 42000E에서 원래대로 코드를 복원하는 부분은 VirtualProtect로 권한을 변경하여 진행하는 등 어셈블리로 진행할 경우 복잡하게 이루어지기 때문에 넣지 않았다. 하지만 실제 C/C++와 같은 언어로 후킹 함수를 제작할 때는 더욱 편리할 것이다.
마지막으로 예제를 통해 진행한 각 방식의 차이에 대하여 알아보자. (A)를 후킹 할 때 해당 주소의 코드를 직접 변경하였는데, 이로 인해 해당 주소가 아닌 지점에서 Sleep()을 호출할 경우 정상적인 Sleep()이 호출된다. 반면에 (B)의 경우 IAT가 가리키는 DS에 존재하는 값을 변경하였고, 이로 인해 Sleep() 함수를 호출하는 모든 곳이 조작된 DS를 가리킨다. 따라서 (B)의 방식의 경우 해당 프로세스에서 Sleep() 함수는 후킹 된 코드 케이브를 지나가게 된다. 마찬가지로 (C) 또한 실제 Sleep() 함수의 부분을 JMP 명령어로 조작하였기 때문에 해당 프로세스의 모든 Sleep() 함수가 후킹된 것이다.
특히 (C)의 방식은 Ntdll.dll의 함수도 조작이 가능하다. 아래의 그림을 보면 실제 Ntdll.ZwDelayExecution을 호출하는 것을 확인할 수 있으며, 해당 부분의 실제 코드의 5 바이트를 JMP 명령어로 수정하여 원하는 후킹을 진행할 수가 있다.

그림 14. Ntdll.dll의 API
단, 이러한 IAT후킹의 경우, 후킹 하고자 하는 함수가 IAT에 존재해야만 후킹할 수 있기 때문에 동적으로 API를 로드(예로, GetProcAddress API 등을 통해)하는 경우 IAT를 참조하지 않아 IAT 후킹을 사용할 없다. 또한 IAT는 프로세스마다 각각 존재하기 때문에 a.exe의 IAT를 후킹하였다고 b.exe까지 후킹 된 것이 아님을 유의해야 한다.
Message Hooking
윈도우 운영체제는 사용자에게 GUI를 제공해주고, 사용자는 제공받은 GUI를 이용하여 원하는 동작을 할 수 있다. 동작을 수행하는데 있어 마우스를 움직이거나 클릭, 또는 키보드 버튼을 누르게 되는데 이러한 동작은 윈도우 운영체제가 Event Driven 방식으로 처리한다. 다시 말해 이러한 동작을 이벤트로 발생시켜 운영체제가 그 이벤트에 맞는 메시지를 해당 응용프로그램에게 전달하여 처리하는 방식이다.
아래 그림을 보면 메시지 후킹이 어떤 지점에서 이루어지는지 나타낸 것이다. 사용자가 어떠한 행위를 했을 때 이벤트가 발생되고, 이벤트 발생으로 인해 OS에서 응용프로그램으로 보낼 메시지들이 OS Message Queue에 존재하고 있다. 예를 들어 키보드 입력 이벤트가 발생하면 WM_KEYDOWN 메시지가 OS Message Queue에 추가된다. 운영체제는 해당 이벤트가 어느 응용프로그램에서 발생했는지 파악한 다음, 큐에서 메시지를 꺼내어 해당 응용프로그램의 메시지 큐에 전달한다. 해당 응용프로그램은 자신의 Application Message Queue에 WM_KEYDOWN 메시지가 추가된 것을 확인하고 해당 이벤트 핸들러를 호출한다. 이러한 방식으로 윈도우는 메시지를 전달한다.

그림 15. 메시지 전달 방식
재미있는 사실은 윈도우 운영체제에서 이러한 메시지 훅기능을 기본적으로 제공한다는 것이다. 바로 SetWindowsHookEx API가 그 주인공으로 훅 체인에 응용프로그램이 정의한 후크 프로시저를 설치하며 이를 통해 사용자는 특정 유형의 이벤트를 모니터링 할 수 있다.
HHOOK WINAPI SetWindowsHookEx( _In_ int idHook // 훅 종류 _In_ HOOKPROC lpfn, // 지정한 이벤트 발생시 처리하는 프로시저 주소 _In_ HINSTANCE hMod, // lpfn이 있는 DLL의 핸들 _In_ DWORD dwThreadId ); |
그림 16. SetWindowsHookEx API
만약 해당 API를 구현하는 HookKey.dll이 존재하며 이를 실행하기 위한 HookMain.exe를 제작하였다고 가정하자. HookMain.exe를 실행하면 HookKey.dll이 해당 프로세스에 로드되며 SetWindowsHookEx()가 호출된다. 이렇게 메시지 후킹이 걸린 상태에서, 다른 프로세스가 해당 이벤트를 발생시킨다면 HookKey.dll은 그 프로세스에서도 로딩이 된다.

그림 17. DLL Injection
위 그림과 같이 나타낼 수 있으며, 다시 말해 후킹 된 이벤트가 발생하는 모든 프로세스에 DLL 인젝션이 일어나는 것이다. 이러한 방식을 통해 메시지를 후킹할 수 있으며, 이는 DLL 인젝션의 한 방법으로 사용할 수 있다.
'Reversing > Theory' 카테고리의 다른 글
| 윈도우 후킹 원리 (3) - Kernel [SSDT] (0) | 2016.04.23 |
|---|---|
| 윈도우 후킹 원리 (2) - Kernel [SYSTEM CALL] (0) | 2016.04.23 |
| System Call & SSDT Hooking (0) | 2016.04.10 |
| BOF에 취약한 함수 (1) | 2016.03.30 |
| 윈도우 메모리구조와 메모리분석 기초 (3) | 2016.03.29 |














































